
Lancers Engineer Blog をご覧のみなさんこんにちは。開発部/技術基盤 SREの安達(@adachin0817)です。最近埼玉で激安マンションを購入しまして、快適な環境でバシバシとフルリモートワークを行っております。今年の目標はより健康的に、ジョギングは毎週続いているので筋トレを取り入れたいと思っております。
さて、ようやくLancers本家の各サーバーをAmazon Linux2化、管理画面をECS/Fargate化、ログ基盤リニューアルを半年で実現できまして、一旦落ち着くことができました。苦労したところなど振り返ってみようと思います。
※去年12月に以下今期SREチームの取り組みについて書きましたが、見ていない方はぜひ一読してもらえると幸いです。
Lancers本体をAmazon Linux2化するにあたって
・2018年 ランサーズのサーバー構成

- 現在 ランサーズのサーバー構成

さてLancers本家ですが、今まではApp、管理画面(Admin)、BatchサーバーはAmazon Linux1で運用していました。また、デプロイ方法としては独自のシステム(Rails/Jenkins)で運用しています。しかしながらAmazon Linux1は2020年6月3日にセキュリティアップデートの提供が終了し、その後SREチームはLancers AgencyやMENTAなどグループ会社のインフラリプレイスも重なったのと、対応することが厳しかったというのがありました。そこでグループ会社のコンテナやログ基盤のノウハウを確立できたということもありまして、移行を決意しました。また、同時にMySQL8化も取り組みました。
SREチームの体制について

SREチームの体制としては前回のブログでも書きましたが、3人で担当しています。今まで私がグループ会社を担当していましたが、波平/@kata_devがジョインしてくれたこともありまして、オンボーディングを行いながら、代わりに運用、改善、新サービスのインフラ構築担当をしてもらっています。そして金澤/@yakitori009と私でLancersを担当していきましたが、波平/@kata_devがジョインしてくれなければまったく進まなかったのもありますし、非常にありがたかったなと感じております。
Lancersは一部Terraform化をしているが完全ではない

Lancersのグループ会社は全てTerraform化されていますが、本家は一部しかTerraform化されていません。EC2での構築は独自のawscliで自動化していましたが、それ以外は手動で設定をしていました。一部のTerraform化でも、例えばECSの部分でセキュリティーグループ、サブネット、ターゲットグループIDなどをそのまま指定しているところが多い状況です。この機会に全てをterraform import化をするには工数がかかってしまうため、フェーズ1として以下に絞りました。
■フェーズ1
・VPC
・サブネット
・ルートテーブル
・インターネットゲートウェイ
・Natゲートウェイ
・エンドポイント
・セキュリティグループ
・EC2
・ELB
・ターゲットグループ
・リスナールール
・RDS
・ACM
まずは様々なエンジニアメンバーがAWSの操作していたということもあり、不要なセキュリティグループなどの棚卸しから始まりました。ステージングと本番環境合わせて約1ヶ月半かかりましたが、なんとかコード化を実現できました。以下TerraformでのCI/CD周りなどの運用方法はCircleCIユーザコミュニティミートアップでもLTしておりますので参考にしてみてください。
来期はフェーズ2として以下terraform import化を行う予定です。
■フェーズ2
・Route53
・S3
・API Gateway
・Lambda
・CloudFront
AppサーバーをECS/Fargateに移行するタイミングは今ではない
コンテナのノウハウがあるのにも関わらず、なぜAmazon Linux2に移行?と思われる方が多いと思います。本家のソースコードは現状肥大化しており、フロントエンドのソースコードは5GB以上もあります。yarn installで30分以上かかってしまうため、コンテナの場合デプロイする時間が膨大にかかってしまうからです。来期はフロントエンドのリポジトリを分割するところから進めていく予定です。
管理画面(Admin)はECS/Fargateへ移行
また管理画面(Admin)は現在CakePHP2から4に移行している最中なので、Cake2はEC2で、Cake4はECS/Fargateで動作しています。コンテナのデプロイ方法としては以下、MENTAと同様にCircleCIで行っています。
- CircleCIによるコンテナデプロイ



- 社内での感謝
- MENTAをAWSに移行して振り返る(ECS/Fargate+Laravel編)
ログサーバーが単一障害点
・EC2で運用している分析基盤サーバー(Digdag + Embulk)をECS/Fargateに移行しました

ランサーズでは分析基盤(Digdag/Embulk/BigQuery/Redash)を運用しており、ログ基盤(Fluentd)を運用していました。もともとAppサーバーにFluentdを常駐させ、ログサーバーにアクセスログやアプリケーションログを転送とS3格納後、Digdag/EmbulkでBigQueryにシンクをしていました。しかし、正常に動作していない状態が度々見受けられ、ブラックボックス化になってしまうことが起きました。そして単一障害点になってしまうという課題がありました。そこで、td-agentのバージョンアップを試みましたが、うまくいかずといったことが重なったため、ログサーバーを廃止して、awslogs/CloudWatch LogsとAmazon Kinesisに乗り換えました。
awslogs/CloudWatch LogsとAmazon Kinesisを使ったログ基盤を実装


開発メンバーでも、サーバーにログインせず、手軽にログ調査をできるように、CloudWatch Logs(awslogs)を採用しました。CloudWatch LogsであればAWSでIAMユーザーをreadonlyで作成すれば、エンジニア以外でも調査しやすくなりますし、簡単にCSVでもダウンロードが可能です。また、比較的学習コストが低いのもメリットです。以下管理画面/ECS/Fargateはstdoutせずにコンテナ内にログを配置して、awslogsを直接インストールしています。
- awslogs.conf
[general]
state_file = /var/lib/awslogs/agent-state
## nginx
[/lancers/app/nginx/access.log]
datetime_format = %d/%b/%Y:%H:%M:%S %z
file = /var/log/nginx/access.log
buffer_duration = 5000
log_stream_name = {instance_id}
initial_position = start_of_file
log_group_name = /lancers/app/nginx/access.log
[/lancers/app/nginx/error.log]
datetime_format = %d/%b/%Y:%H:%M:%S %z
file = /var/log/nginx/error.log
buffer_duration = 5000
log_stream_name = {instance_id}
initial_position = start_of_file
log_group_name = /lancers/app/nginx/error.log
## cakephp log
[/lancers/app/logs/cakephp_log]
datetime_format = %Y/%m/%d %H:%M:%S
file = /var/www/lancers/logs/*.log
buffer_duration = 5000
log_stream_name = {instance_id}
initial_position = start_of_file
log_group_name = /lancers/app/logs/cakephp_log
~省略~- 管理画面 本番Dockerfile
FROM amazonlinux:2
ENV APP_ROOT /var/www/lancers_admin
ENV LANG ja_JP.utf8
ENV LC_ALL ja_JP.utf8
WORKDIR $APP_ROOT
# Install amazon-linux-extras
RUN amazon-linux-extras install -y epel
RUN amazon-linux-extras enable nginx1
RUN yum update -y && \
yum -y install \
awslogs \
gcc \
gd \
git \
glibc-langpack-ja \
keyutils-libs-devel \
libXpm \
libedit-devel \
libpng \
libselinux-devel \
libtiff \
libtool \
libverto-devel \
libwebp \
libxslt \
passwd \
procps \
python-pip \
sudo \
supervisor \
unzip \
vim \
xz-devel \
yum-utils \
zlib-devel
RUN amazon-linux-extras install -y \
nginx1 \
php7.3
# Install php common
RUN yum -y install \
pcre-devel \
php-cli \
php-common \
php-devel \
php-gd \
php-intl \
php-mbstring \
php-mysqlnd \
php-pear \
php-pecl-apcu \
php-process \
php-fpm \
php-opcache \
php-redis \
php-soap \
php-xml \
php-zip \
https://github.com/DataDog/dd-trace-php/releases/download/0.70.1/datadog-php-tracer-0.70.1-1.x86_64.rpm \
&& \
yum clean all
# Setup UTC+9
RUN unlink /etc/localtime
RUN ln -s /usr/share/zoneinfo/Japan /etc/localtime
#Create lancers user
RUN useradd -u1000 lancers \
&& passwd -d lancers
RUN sed -ri 's/^wheel:x:10:/wheel:x:10:lancers/' /etc/group \
&& sed -ri 's/^# %wheel/lancers/' /etc/sudoers
# awslogs need pip install requests
RUN pip install --upgrade pip
RUN pip install requests
# make directory
RUN mkdir -p $APP_ROOT
COPY . $APP_ROOT
# php composer.phar install
RUN php composer.phar install
# copy src
COPY docker/prd/app-admin/src/environment.php /usr/local/src/environment.php
# nginx
COPY docker/prd/app-admin/nginx/default.conf /etc/nginx/conf.d/default.conf
COPY docker/prd/app-admin/nginx/fastcgi.conf /etc/nginx/conf.d/fastcgi.conf
COPY docker/prd/app-admin/nginx/header.conf.include /etc/nginx/conf.d/header.conf.include
COPY docker/prd/app-admin/nginx/krgn2.conf /etc/nginx/conf.d/krgn2.conf
COPY docker/prd/app-admin/nginx/log.conf.http /etc/nginx/conf.d/log.conf.http
COPY docker/prd/app-admin/nginx/nginx.conf /etc/nginx/nginx.conf
RUN rm -rf /etc/nginx/conf.d/php-fpm.conf
# awslogs
RUN mv awscli.conf /etc/awslogs/
COPY docker/prd/app-admin/awslogs/awslogs.conf /etc/awslogs/awslogs.conf
COPY docker/prd/app-admin/logrotate/awslogs /etc/logrotate.d/awslogs
# PHP
COPY docker/prd/app-admin/php/php.ini /etc/php.ini
COPY docker/prd/app-admin/php/40-apcu.ini /etc/php.d/40-apcu.ini
COPY docker/prd/app-admin/php-fpm/php-fpm.conf /etc/php-fpm.conf
COPY docker/prd/app-admin/php-fpm/www.conf /etc/php-fpm.d/www.conf
## Setting supervisor
COPY docker/prd/app-admin/supervisor/supervisord.conf /etc/supervisord.conf
COPY docker/prd/app-admin/supervisor/app.conf /etc/supervisord.d/app.conf
RUN chmod 777 logs
RUN chmod 777 tmp
RUN touch logs/dummy.log
# Service to run
CMD ["/usr/bin/supervisord"]またログ基盤もあらゆるログが転送されていることもあったので、ポリシーを見直しました。
・NginxアクセスログはS3に集約
・CloudWatch Logsには永続
・アプリケーションログは分析用途として利用せずにS3には集約しない
・CloudWatch Logsには1ヶ月保持
・決済ログは3ヶ月保持
・ActivityログはAPI経由で実装を変更する
アクセスログはJSONファイルでS3に格納されていましたが、生ログではなかったので、LTSV形式のままAmazon KinesisでLambdaを使い変換後、S3に集約するようになりました。これによりローカルでもアクセスログを確認したい場合も調査しやすくなりました。また、Amazon Kinesis Data Firehoseの設定でスループット上限を超過する場合、PutRecordBatchの上限である、コールごとに最大500レコード、または4 MBの制限があり、ServiceUnavailableExceptionが出る可能性があるので、Transform側のBuffer sizeとBuffer intervalは1MBと60秒にしてバッファ間隔を短くしています。
※Kinesisの設定等は以下個人ブログ書いてますので参考に
[AWS][Terraform]CloudWatch LogsのアクセスログをLambdaでLTSV形式に変換してKinesisでS3に保存する
Amazon Kinesisは他のサービスでも連携がしやすく、DatadogではAPMの監視はしていたものの、ログ周りのモニタリングは以前Kibanaを利用していましたが、DatadogのLogsに統一しました。Logsを新たに利用してリアルタイムにNginxのエラーログ、アプリケーションログ、スロークエリを可視化することで可観測性を高められるようになりました。エラーが出た場合もSlack通知するようにしているので、突発的なログも早期発見することが可能になりました。Datadog Logsのプランですが、7日間のみ保持するようにしているのでコストは月に$1000ほど上がりました。毎月10万ほと増えてしまうので、Nginxのログは連携せずに、アプリケーションログのみにしました。これにてログサーバーを撤退することができましたし、ECSにもawslogsをインストールさえすればログの転送も可能なので、コンテナに移行する準備も整うことができました。


[AWS][Terraform]CloudWatch LogsをKinesis Data Firehose経由でDatadogに転送する
開発環境の修正

ランサーズの開発環境は本番環境と同じ構成を再現しております。ステージングや本番環境はAnsibleを利用しているので、開発環境用のAnsibleコンテナを動かして自動化しています。まずAnsibleのメンテナンスを怠っていたということもあるので、Ansibleの修正から行いました。変更点は以下となります。
・Docker Imageはamazonlinux2
・AnsibleコンテナをAmazon Linux2にリプレイス
・serviceからsystemdに
・supervisorでプロセス管理
・MySQL8化に伴い、mysql80-communityのインストール
・不要なパッケージを洗い出し削除
・amazon-linux-extrasによるPHPインストール
・ログサーバー廃止に伴いtd-agentの削除とawslogsのインストール
・管理画面はAnsibleから削除してDockerfileを一からbuildして構築
開発環境のMySQLコンテナ8化は完了しましたが、STRICT_TRANS_TABLESを有効化しようと試みましたところnot null カラムに null が入る実装があったり、fixtureのクエリがエラー出てしまっていたため、sql_modeは0に変更し、一旦見送ることになりました。MySQL8化については別ブログで詳しく書きたいと思います。1週間ほどQAチームに動作確認をしてもらい、切り替えが完了しました。
ステージング/カナリア/本番環境の構築
新たなApp(EC2)、Batch(EC2)、管理画面(ECS)はTerraform/Ansibleを利用して、Amazon Linux2はArmで構築をしました。しかし、DatadogのAPMで利用しているdd-trace-phpがArmをサポートしていないということが判明しましたので、本番環境ではArmを断念することになりました。ただArmサポートは進んでいるようなので継続的に情報を待ち続けたいと思います。
https://github.com/DataDog/dd-trace-php/issues/1252
またECS/FargateもArmをサポートしましたが、CircleCIのOrbsがまだ対応していないのでこちらも待ちとなります。(もうすぐリリースされそう)
https://github.com/CircleCI-Public/aws-ecs-orb/pull/141
管理画面(Admin)、Batchはメンテナンスせずに事前に切り替えをして、Kinesisでのログ確認を行い、当日メンテナンスの切り替えはAppのみにしました。
本番移行メンテナンス実施
本番移行は3/23の2時から実施しました。以下実施したことをまとめました。
・リスナールールでメンテナンスモード
・旧インスタンスをターゲットグループから外す
・新Appサーバーをターゲットグループに追加
・KinesisによるログがS3に集約されているか確認
・オートスケールによるAMI作り直し
・Aurora MySQL5.7をスナップショット
・TerraformによるAurora MySQL8を復元
Aurora MySQL8の不具合
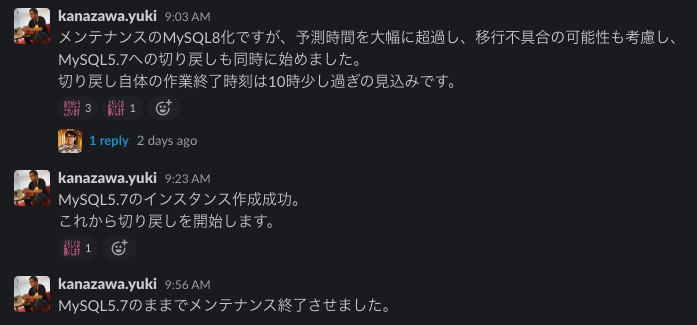
最後の最後でトラブルが発生しました。Aurora MySQL8の復元が何時間待っても終わらず、メンテナンスの予測時間を大幅に伸びてしまうことが起きました。ステージング環境では問題なくTerraformで復元できましたが、本番環境では想定外のことが起き、結局MySQL5.7への切り戻しを同時に始めたところ、5.7では1時間ほどで復旧することができました。そしてちょうどメンテナンスが終わった午前10時過ぎにAWS側から不具合の連絡が来たので、色々とタイミング等合わなかったと感じております。来月はMySQL8化に挑みたいと思います。
まとめ

ついにLancers本家のAmazon Linux2化とログサーバーを撤廃し、Kinesisに移行完了!そしてAurora MySQL8化に挑んだものの、終わらず…AWSから不具合報告が来た…😇
— adachin👾SRE (@adachin0817) March 23, 2022
ランサーズは10年以上運用しているサービスとなります。長い月日を経て本家のインフラ周りを少しずつモダンな形に前進しつつ、安定性も向上してきていると感じています。
今回、一番達成感を感じるのはログサーバーの廃止です。ログサーバーは私が入社する前から運用していたので、何が何なのかわからない状態でした。マネージドサービスに移行することができて嬉しく思います。
今回サポートしてくれたQAチームとSREチームでの協力がなければ達成することができませんでしたし、感謝しております。が、まだMySQL8化が残っています。MySQL8ではDatadogのDatabase Monitoringを導入し、来期はAppをECS/Fargateに移行し、独自のDeployシステムを廃止とCircleCIでのリリースに統一をする予定です。その時はまたブログで報告したいと思います。SREチーム募集していますので興味がある方は連絡ください!
※本体のAppもコンテナに移行しました