
Lancers Engineer Blog をご覧のみなさんこんにちは。開発部/技術基盤 SREの安達(@adachin0817)です。以下前回のブログから3ヶ月経ちましたが、ついにLancersのBatch、AppサーバーをEC2からECS/Fargateに移行完了しました。
そして長年自前で運用していたデプロイシステムを廃止して、CI/CDはCircleCIに完全統一しました。これにて、Lancersの全サービスをコンテナに移行完了となりました。
※見ていない方はぜひ一読してもらえると幸いです。
・LancersをAmazon Linux2へログ基盤のリニューアルと管理画面をECS/Fargateに移行しました
旧開発環境、EC2での運用課題
- Ansibleコンテナによる開発環境の統一により工数がかかる
本番コンテナ化以前は、EC2で利用しているAnsibleの管理を開発環境にも適用するために、開発コンテナの構築も(Dockerfileではなく)Ansibleで行っていました。開発コンテナをAnsibleで構築する運用は、ECRで共用する必要がありました。パッケージの更新やNginxの設定などを変更するたびにコンテナを作り直してECRに都度pushする必要があり、SREの工数がかかる要因の一つになっていました。
- Ansible修正後にオートスケールの再設定でAppサーバーを作り直さなければならない
Ansibleのplaybookの修正が入ると、オートスケールの起動に利用するAMIの更新が必要になります。ステージング、カナリア、本番環境のAppサーバーとオートスケールを作り直さなければなりません。また以下のように手動で設定をするというトイルが残ったままでした。
・AMI専用のEC2を起動し、Ansible実行
・AMIを取得後、オートスケールの起動設定をコピー
・Auto Scaling グループから起動タイプを最新に変更
ECS/Fargateであればこの部分をDockerfileとデプロイだけで済むので工数がかからないというメリットがあります。
- 自前のデプロイシステムが属人化されてしまっており、不具合の対応に工数がかかる
こちらは後述します。
開発環境の改善
- これまでの開発環境

- 新開発環境
$ tree docker/dev/app
docker/dev/app
├── Dockerfile
├── README.md
├── awslogs
│ ├── awscli.conf
│ └── awslogs.conf
├── devx.sh
├── nginx
│ ├── _default.conf
│ ├── api.conf
│ ├── header.conf.include
│ ├── krgn.conf
│ ├── log.conf.http
│ ├── nginx.conf
│ ├── www.conf
│ ├── www.conf.proxy
│ └── www.conf.rewrite
├── php
│ ├── 15-xdebug.ini
│ ├── 40-apcu.ini
│ └── php.ini
├── php-fpm
│ ├── php-fpm.conf
│ └── www.conf
├── postfix
│ ├── main.cf
│ └── postfix.sh
├── src
│ ├── DatabaseDriver.php
│ ├── environment.php
│ └── operation_mode.php
└── supervisor
├── app.conf
└── supervisord.confDockerfileによる一般的な運用になりました。また、別リポジトリ(playbook)で管理していた開発環境は、Lancers本体のリポジトリに統一しました。Docker ImageはAmazon Linux 2を利用しています。pine Linuxと比べるとパフォーマンスが良いと言われており、パッケージインストールのしやすさにより選択しました。
アクセス/アプリログは管理画面と同様にawslogsでシンク

ログサーバーを撤廃して、新ログ基盤であるAmazon Kinesisに移行して3ヶ月経ちました。今の所特にトラブルなく運用できている状況です。アクセスログやアプリケーションログはEC2時代と同様にコンテナでもawslogsを利用してCloudWatch Logsにシンクし、LambdaでLTSV形式に変換後、アクセスログのみKinesisでS3に保存しています。ちなみにAppコンテナはphp-fpm、Nginxを一つのコンテナ内で動作するようにしていますが、分離してしまうとシンプルではなくなってしまうと判断しました。また、FireLensもありますが、ログをstdoutする前提といったことから、現構成だと複数のログディレクトリを参照することができません。サイドカーとしてFluent Bitを利用する場合はコンテナを分離しなければならないでしょう。
またこの機会に分析基盤として利用しているRedashもECS/Fargateへ移行しました。オートスケーリングに対応したことにより、負荷の増大に自動的に対応できるようになりました。
BatchサーバーはECS Scheduled Taskに移行

Lancersのバッチは100個以上あります。今までBatchサーバーは冗長化せずEC2 1台のみで運用していたため、サーバーダウンやAZ障害が起きると、サービスに影響が出てしまう状況でした。そこで、CakePHP4で実装されているバッチ約80個のみECS Scheduled Taskに移行することで、Terraformで開発メンバーが管理できるようにしました。これにより、バッチ運用が冗長化され、耐障害性が上がりました。Cronで標準エラー出力をメール通知していた処理は、ECS Scheduled Taskで、CloudWatch Logs、SNS、Lambdaを利用してエラーのキーワードを検知し、Slack通知させる処理にしました。
残りのCakePHP2で動作しているバッチは現在QAチームが移行していますので、今後Batchサーバーは廃止していく予定になります。Scheduled Taskに移行すると、Nat Gatewayの通信費用が上がりますが、VPCエンドポイントを挟めば全体の費用は6分の1に削減されるため、コスト削減に効果的です。
CakePHP4のバッチはSendGridでメール送信するように実装していますが、一部Postfixを利用するバッチが残っています。Scheduled Taskは1コンテナにつき1プロセスしか実行できないため、工夫しないとメールを送信出来ませんでした。以下のようにSupervisor(Postfix)とPHPのバッチコマンドを実行するシェルスクリプトを書くことで対応しました。
#!/bin/bash
/usr/bin/supervisord &
sleep 10
/var/www/lancers_batch/bin/cake NewWorkEmail
sleep 10フロントエンドの改善
前回のブログで「AppサーバーをECS/Fargateに移行するタイミングは今ではない」と話していましたが、ネックとなっていたのがフロントエンドのビルド処理でした。この問題を、フロントエンドのリポジトリを分割することで対応しようと考えていましたが、今のフロントエンドのソース構造上、パスによる処理分割が困難で工数がかかることから、一旦中止しました。
毎回リリース時にyarn install,buildをしてしまうと、CIでのビルドに10分以上かかってしまうので、予めローカルでビルドして生成されたファイルをGit管理する運用にしました。
以前の運用に戻した形になりますが、現状はこれが最善と判断しました。これにより、リリース時にyarn installは不要になり、CI時間が大幅に短縮されたため、Appサーバーのコンテナへ移行できる条件が整いました。
リポジトリの分割、およびCIでビルドする運用は将来再度検討予定です。
自前デプロイシステム(Deploy-San)について


自前デプロイシステムは通称「Deploy-San」と呼んでいました。Deploy-Sanは2015年頃に作られたシステムで、Ruby on RailsとJenkinsで実装されていました。Deploy-sanがGitHubからコードをpullした後にaws-cliでEC2のhostsを検知して、独自のシェルスクリプトでEC2にrsyncを実行する仕組みとなっていました。オートスケーリング時には、AMIからEC2サーバーを起動した後、Deploy-sanから最新のコードを取得していました。そのため、Deploy-sanが単一障害点になっていました。
独自のシェルスクリプトで差分更新し、リリース時間は1分以内に完了していました。コンテナになると、CircleCIでDockerfileのbuildから行うため、デプレイ時間が最低でも4分はかかってしまいます。しかしながら、CI/CDをCircleCIで一本化し、Immutableな運用になります。特にオートスケーリング時のソース更新等の考慮が必要なくなり、運用が極めてシンプルになりました。
CircleCIでのコンテナデプロイについて
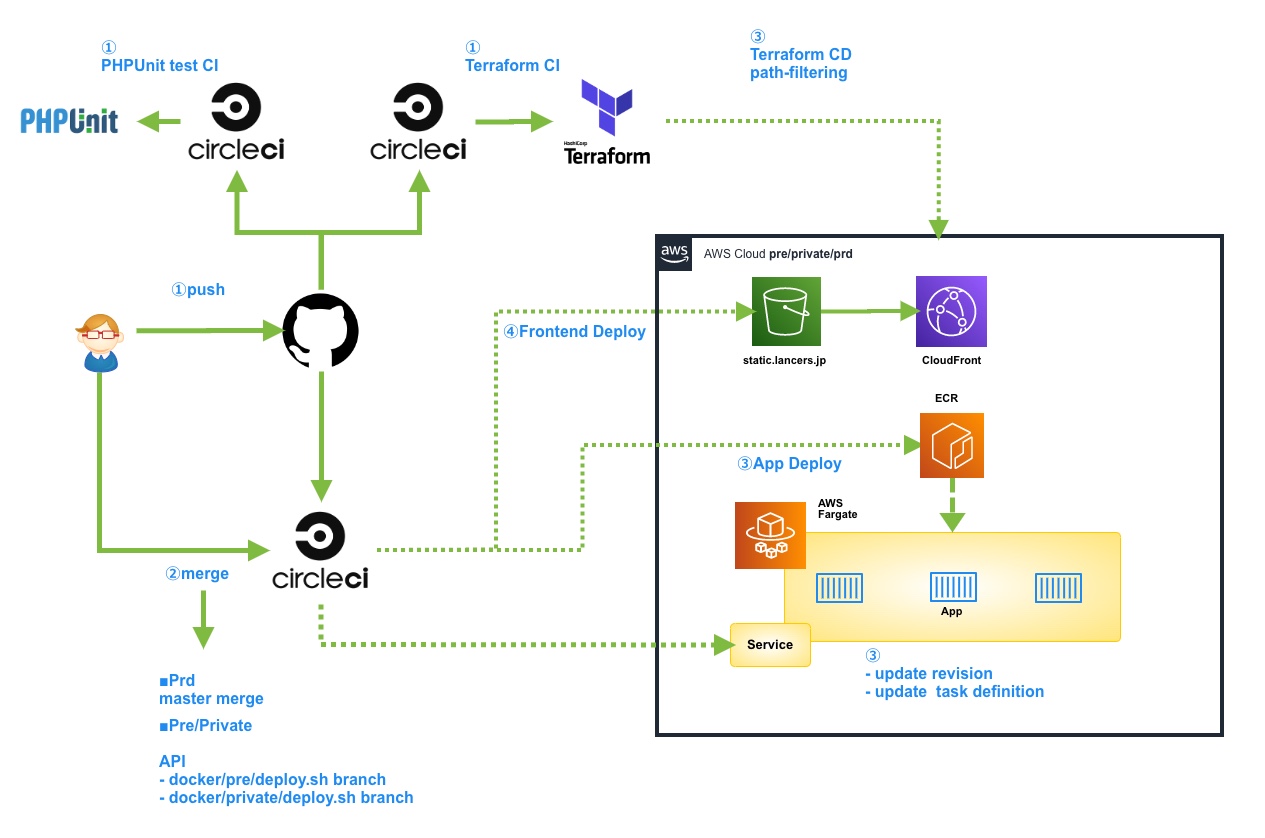
このデプロイフローはグループ会社で培ったノウハウとまったく同様で、ステージング環境(Pre)、カナリア環境(Private)ではCircleCIのAPI/Trigger Pipelineを利用しており、好きなタイミングでAppコンテナをデプロイできるようになりました。また、Masterマージすることで本番環境にデプロイされます。それ以外のCIはPHPUnit、Terraform、CDとしてTerraformの差分(path-filtering)があればapplyされるような仕組みになりました。
- コンテナデプロイ高速化

コンテナによるデプロイ時間は当初は10分以上かかっていました。デプロイ時間短縮策のために、以下の対策を行い、最終的にはデプロイ時間を5分以内まで縮めることができました。
・.dockerignoreによる.gitなどコンテナ内にコピーされないように修正
・Dockerfileで不要なパッケージの棚卸し
・CircleCIのcheckout_shallowを利用、depth: 1、fetch_depth: 1で最後のコミットのみコピー
・remote-docker-layer-cachingを有効化

負荷対策とコンテナコスト削減
コンテナ移行後は、サーバーレスポンスタイムが若干悪くなりました。EC2(c5系インスタンス)で運用していたときとCPU数、メモリ容量は同じ設定にしているのですが、ECSで使われているCPUは現状選択できないため、今後のCPU改善に期待したいです。
オートスケールの台数は最小で3台、最大で20台に設定しました。Fargate Spotも導入し、既存の3台はFargateで、オートスケールはFargate Spotで運用しています。
Fargate Spotは突然コンテナが落ちる可能性を想定し、Datadogでモニタリングしています(ECS Scheduled Taskも同様)。Fargate Spotに関しては個人ブログを参照ください。ちなみに、ECSはArm系CPUもサポートしていますが、現状はCircleCI側が対応していません。対応し次第移行する予定です。
- php-fpm/www.conf
pm = static
pm.max_children = 150
pm.start_servers = 150
pm.min_spare_servers = 150
pm.max_spare_servers = 150
pm.process_idle_timeout = 10s;
pm.max_requests = 300
request_terminate_timeout = 100- ecs-lancers.tf
capacity_provider_strategy {
base = 3
capacity_provider = "FARGATE"
weight = 0
}
capacity_provider_strategy {
base = 0
capacity_provider = "FARGATE_SPOT"
weight = 1
}移行後のレスポンスについて
EC2のサーバーレスポンスを比較しても数十msほどの差分でした。
- EC2

- ECS

- 移行後のAppコンテナの負荷について
ランサーズは日中に負荷がピークになるサービスです。EC2時代と比べてCPUパフォーマンスが落ちる可能性が高いことを予想していたため、とりあえず、オートスケールはCPU20%以上で実行されるように余裕を持って設定しました。
EC2

ECS
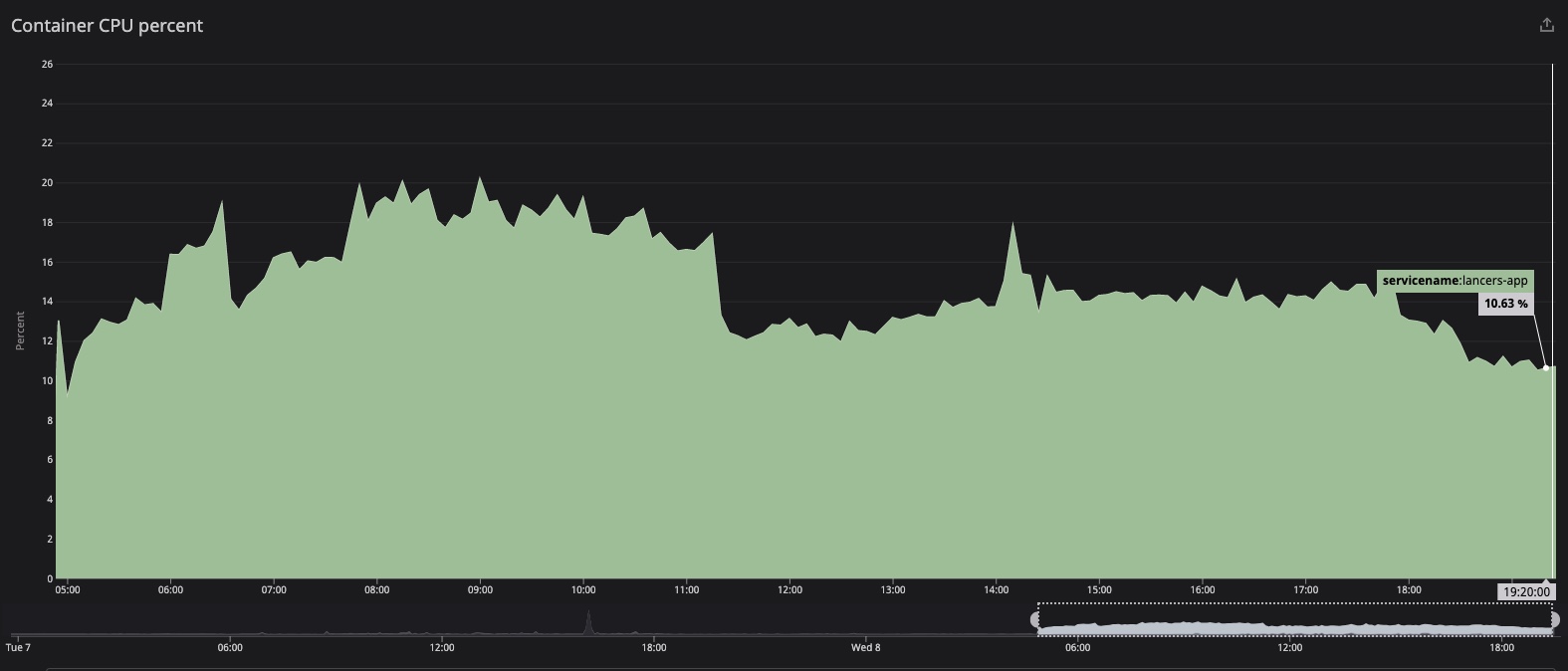
パフォーマンスに問題がないことを確認しながら、台数、およびCPU負荷をチューニング中です。引き続きモニタリングしていきます。
まとめ
入社してから4年で、グループ会社の各サービスでコンテナ運用のノウハウを蓄積し、その集大成をLancersに投入しました。今回のコンテナ移行によって、SREのトイル削減、および、開発部全体のリリースフロー改善による生産性向上が期待できます。今後もフロントエンドのモダン化や、PHP/CakePHPのバージョンアップも進め、より開発メンバーが開発しやすい環境にしていきます。
入社して4年経ったが、この度ようやくLancersのサービスを全てコンテナに移行することができた。感無量である🙌
— adachin👾SRE (@adachin0817) June 8, 2022
最後に、移行プロジェクトを経て1年かかりましたが、個人の力では本家コンテナ化をやりきることができなかったと思います。SREチームの協力があって達成することができました。改めてありがとうございました。まだまだ改善の余地はありますし、ここから新しい仕組みでエンジニア全員が運用できるようになれれば幸いです。次回はMySQL8化についてブログしたいと思います。
※dipさんと登壇してきましたので参考に!
> [Lancers x dip]第1回 Engineer Meetup を開催しました!
全サービスコンテナ移行やりきったのでSREチームMVP取ったぞ!!お疲れ!🎉🙌 pic.twitter.com/XowcZic9dj
— adachin👾SRE (@adachin0817) July 7, 2022