
SREチームの安達(@adachin0817)です。最近ではランサーズ本家のインフラをコンテナに移行しまくっております。今回ランサーズとMENTAで運用しているEC2/分析基盤サーバー(Digdag + Embulk)をECS/Fargateに移行完了しました。では早速概要と苦労した点、今後の展望などを振り返っていきたいと思います。
分析基盤の紹介

 > ランサーズの分析基盤(capybara)と運用について紹介
> ランサーズの分析基盤(capybara)と運用について紹介
> MENTAをAWSに移行しました
ちなみに私が入社して3年経つのですが、運用して変わったことは3年前よりデータの量が膨大になっていることと、現在、社内の分析チームにとって欠かせないシステムとなっております。その中でDigdagによるスケジューラーとEmbulkによるマルチソースバルクデータローダーである分析基盤専用のEC2サーバーがあり、毎日夜中にデータをBigQuryにシンクしています。もちろんMENTAも同様にグループジョインしてから同様な構成で運用しています。
- 開発環境がない

またEC2サーバー(Amazon Linux 1)では約5~6年以上動いていたということもあり、Ansible化はされているものの一部しかコード化をしておらず、手動でパッケージなどインストールしていたということもあり、2年前Amazon Linux 2にいざ移行しようとしても、ブラックボックスになり始め、メンテナンスがし難い状況でした。
それと分析チームがStgのサーバーにログインして開発するしか手段がないため、作業のカニバリや外部の方の動作検証ができず、非常に開発しづらい状態でした。そのため、開発環境を作ることから始めました。
※上記分析基盤の運用についてブログしていますので参考にしてみてください。
Digdag/Embulk 開発環境


ランサーズの開発環境ですが、MySQLコンテナは毎週本番データをマスクして、AWS CodebuildでECRにpushしています。開発メンバーはMySQLコンテナをpullして本番環境により近い環境で開発を行っています。それに従い、DigdagコンテナとPostgreSQLコンテナを構築して、MySQLコンテナのデータを取り込みBigQueryにシンクするような環境を作りました。また、開発環境のBigQueyシンク先でDev用のプロジェクトを作成しようと思いましたが、管理が増えることから、Stgで利用しているプロジェクトにしました。まずはDockerfileから紹介していきましょう。
- Dockerfile
FROM openjdk:8-alpine
ENV DIGDAG_VERSION 0.9.42
ENV EMBULK_VERSION 0.9.23
ENV GOPATH /go
ENV PATH /usr/local/go/bin:/go/bin:$PATH
ENV LANG C.UTF-8
ENV APP_ROOT /opt/hoge
# Setup UTC+9
RUN apk --update add tzdata && \
cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \
apk del tzdata && \
rm -rf /var/cache/apk/*
# install packages
RUN apk update && \
apk upgrade && \
apk add --update --no-cache \
autoconf \
bash \
curl \
git \
libc6-compat \
make \
mysql-client \
postgresql-client \
py3-pip \
python \
supervisor \
tzdata \
vim
# Install awscli
RUN pip3 install --upgrade pip
RUN pip3 install awscli
RUN mkdir /root/.aws/
COPY digdag/credentials /root/.aws/credentials
# go 1.12.5 install,delete gz
RUN wget https://dl.google.com/go/go1.12.5.linux-amd64.tar.gz --no-check-certificate -P /tmp
RUN tar -C /usr/local -xzf /tmp/go1.12.5.linux-amd64.tar.gz && rm /tmp/go1.12.5.linux-amd64.tar.gz
# google sdk command install
RUN curl -sSL https://sdk.cloud.google.com | bash
ENV PATH $PATH:/root/google-cloud-sdk/bin
RUN mkdir /root/.gcp
# install digdag
RUN curl --create-dirs -o /usr/local/bin/digdag \
-L "https://dl.digdag.io/digdag-${DIGDAG_VERSION}" \
&& chmod +x /usr/local/bin/digdag \
# install Embulk
&& curl --create-dirs -o /usr/local/bin/embulk \
-L "https://dl.embulk.org/embulk-latest.jar" \
&& chmod +x /usr/local/bin/embulk
# Setting Embulk version
RUN embulk selfupdate ${EMBULK_VERSION}
# Setting Digdag
RUN mkdir /etc/digdag
COPY digdag/server.properties /etc/digdag/server.properties
# setting superviser
COPY supervisor/supervisord.conf /etc/supervisord.conf
COPY supervisor/app.conf /etc/supervisor/conf.d/app.conf
RUN echo files = /etc/supervisor/conf.d/*.conf >> /etc/supervisord.conf
# Port to expose *outside* the container
EXPOSE 80
# Service to run
CMD ["/usr/bin/supervisord"]- supervisor/conf.d/app.conf
[supervisord]
nodaemon=true
[program:digdag]
directory=/etc/digdag
command=java -Dio.digdag.cli.launcher=selfrun -XX:+AggressiveOpts -XX:TieredStopAtLevel=1 -Xverify:none -jar /usr/local/bin/digdag server --max-task-threads 2 --config server.properties -b 0.0.0.0 --log /var/log/digdag/digdag_server.log --task-log /var/log/digdag/tasklogs --access-log /var/log/digdag/accesslogs
user=root
autostart=true
autorestart=true
stopsignal=TERM
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0- setting.bq.sh
#!/bin/bash
aws --profile=hoge s3 cp s3://hoge/digdag/kms/bq-encrypt.key /root/.gcp/
aws --profile=hoge kms decrypt --ciphertext-blob fileb://~/.gcp/bq-encrypt.key --output text --query Plaintext | base64 -d > ~/.gcp/bq.key
gcloud auth activate-service-account \
bigquery-embulk@stg-capybara.iam.gserviceaccount.com \
--key-file ~/.gcp/bq.key \
--project stg-capybara今回利用したイメージはopenjdk:8-alpineを選択しました。またDigdagはJavaが必須となり、元々初めはDigdag公式のイメージがないことから、1からAlpineイメージで構築を始めていると、Javaのインストールで不要なパッケージも入ってしまうことからイメージの容量が2GBにも超えてしまい、DigdagのサーバーモードからいくらWebからRunしても起動されないことがありました。なので、openjdkのイメージを利用して構築することをオススメします。それ以外のプログラムでGoも利用しており、リポジトリも分割していることからインストールするようにしています。
プロセス起動管理も同様にsupervisorで整えましたが、Stgや本番コンテナではaccess-log、digdag_server.logはCloudWatchLogsで出力されますので開発環境のみ指定しています。BigQueryで利用するサービスアカウントのJSONファイルはAWS KMSで暗号し、復号化するようにシェルスクリプト化を行いました。それ以外にEmbulkで利用しているDBのパス等は環境変数でenvファイルを利用してS3からコピーするように管理していますが、これも今後はKMSで暗号したほうがよりセキュアになるので改善していきたいと思います。
この開発環境により、digdag run、スケジューラーのテスト、bqコマンドでの操作が簡単にできるようになりました。
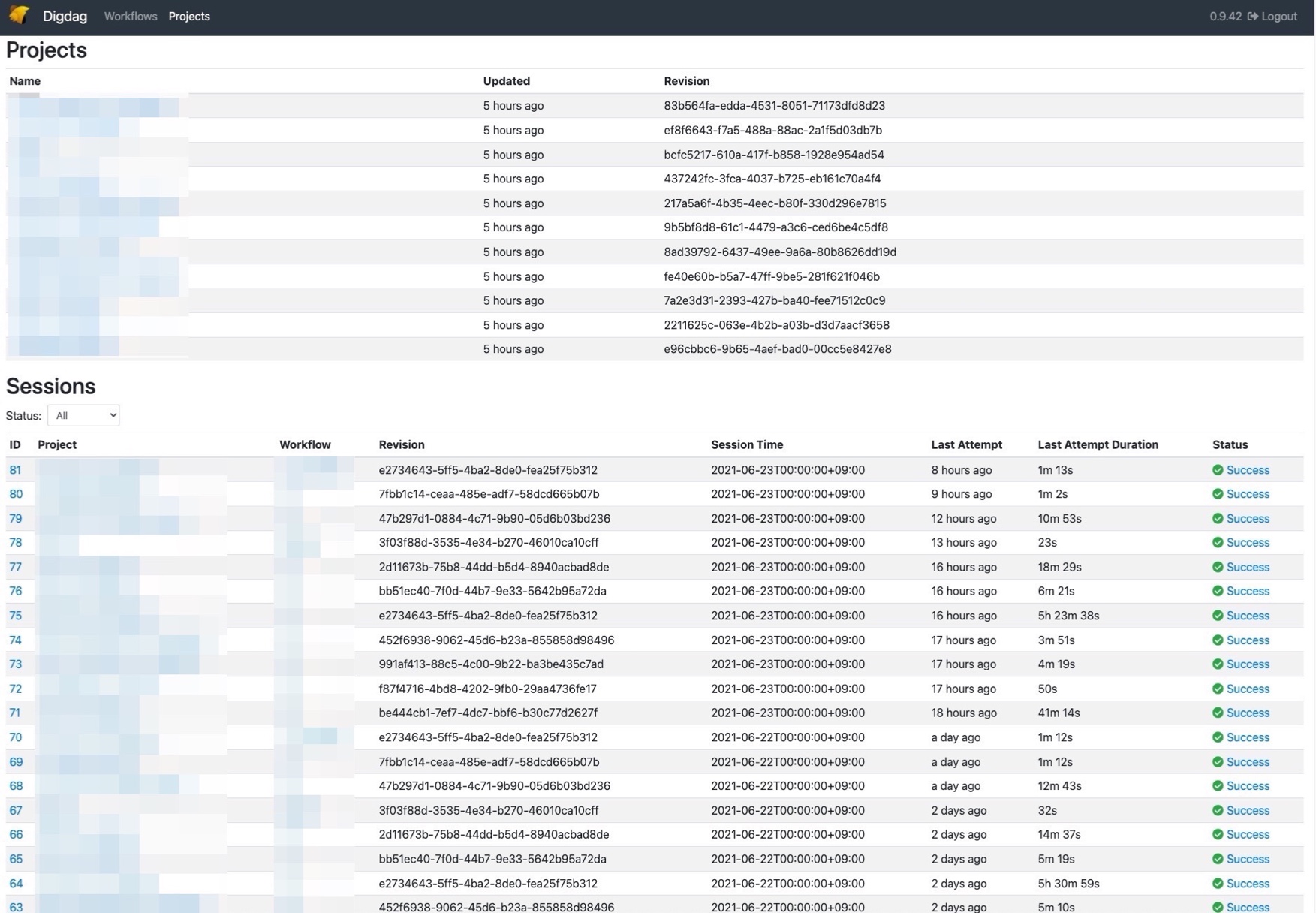
Stg/本番環境

- setting-digdag-secret.sh
#!/bin/bash
## project
PROJECT1=hoge
PROJECT2=hogee
PROJECT3=hogeee
~省略~
# decrypt bq.key
aws --profile=hoge s3 cp s3://hoge/digdag/kms/bq-encrypt.key /root/.gcp/
aws --profile=hoge kms decrypt --ciphertext-blob fileb:///root/.gcp/bq-encrypt.key --output text --query Plaintext | base64 -d > /root/.gcp/bq.key
## setting local mode digdag secrets
cd /root/.gcp/ && cat /root/.gcp/bq.key |digdag secrets --local --set gcp.credential=@bq.key
## setting server mode digdag secrets
for i in ${PROJECT1} ${PROJECT2} ${PROJECT3}
do
cd /hoge/digdag/${i} && digdag push ${i} && digdag secrets --project ${i} --set gcp.credential=@/root/.gcp/bq.key
done
# delete bq.key
rm /root/.gcp/bq.keyStg環境は上記の開発環境のDockerfileを元に構築をし、コンテナデプロイもCircleCIでマージ後にリリースされるようになっております。ちなみにDigdagではサーバーモードとローカルモードと2つあります。分析チームや開発メンバーから、今すぐこのテーブルをBigQueryにシンクしてほしい!といったことがあるため、ECS-ExecでDigdagコンテナにログインして、ローカルモードで実行できるようにしました。ここはEC2にSSHして実行するのと変わりありませんね。
digdag pushは手動で行っていましたが、どんなプロジェクトが動いているのか管理したかったというのもあったので、シェルスクリプトで自動化して、新規プロジェクトが増えた場合はそのシェルを変更してもらうようにしました。
- ViewテーブルのクエリバックアップをECS schedule task化


BigQueryのviewテーブルのクエリは本番環境で間違えて消してもすぐ戻せるようにシェルスクリプト化をしているのですが、今まではEC2のCronからECS schedule taskに移行して、毎日0時に実行されるようにしました。上記のスクリプトは個人ブログ書いていますので参考にしてもらえばと思います。
苦労した点
- 本番環境だけdigdagコンテナが落ちたり上がったりの繰り返しになる
Digdag立ち上げるとエラー出てハマっている..
org.postgresql.util.PSQLException: ERROR: relation "session_attempts_on_site_id_and_state_flags_partial_2" already exists
— adachin👾SRE (@adachin0817) June 16, 2021
Stg環境では動作等問題なかったのですが、移行時に本番環境のみコンテナが落ちて立ち上がるの繰り返しが起きました。実際にコンテナにログインしてデバッグしてみましたが、以下のエラーが出ており、調査に時間がかかってしまうということもあったので、一度DigdagのDBを作り直したところうまくいき、原因不明で移行完了してしまったというのが非常に残念でした。
org.postgresql.util.PSQLException: ERROR: relation "session_attempts_on_site_id_and_state_flags_partial_2" already exists- 本番移行時にエラーが多発する
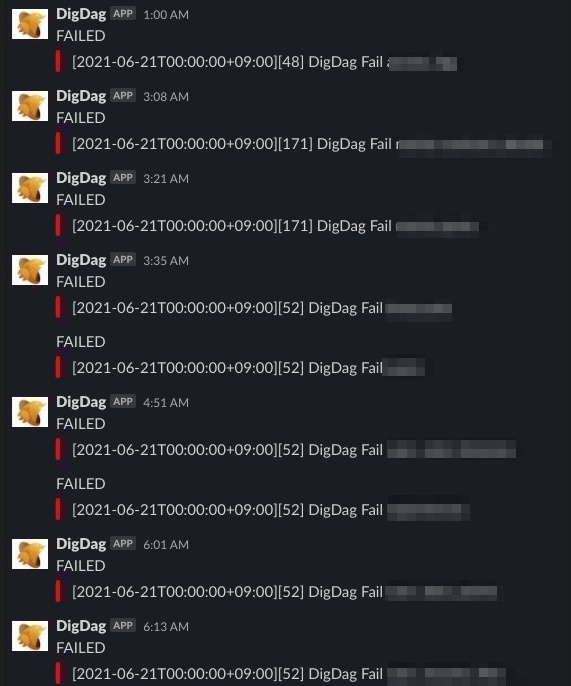
embulkのプラグインでembulk-output-bigqueryを利用しているのですが、深夜のシンクで10分に1回以下のエラーが多発しました。プラグインのバージョンアップをしたところ多発することが少なくなったので、以前と同じで100以上あるテーブルのシンクに5時間で完了できるようになりました。
※以下追記
[Digdag]チューニングとFailed to add subtasks because of task limitについて
Error: OutputPlugin 'bigquery' is not found.今後の改善と展望
- envファイルをKMS化
- コンテナデプロイが遅すぎる
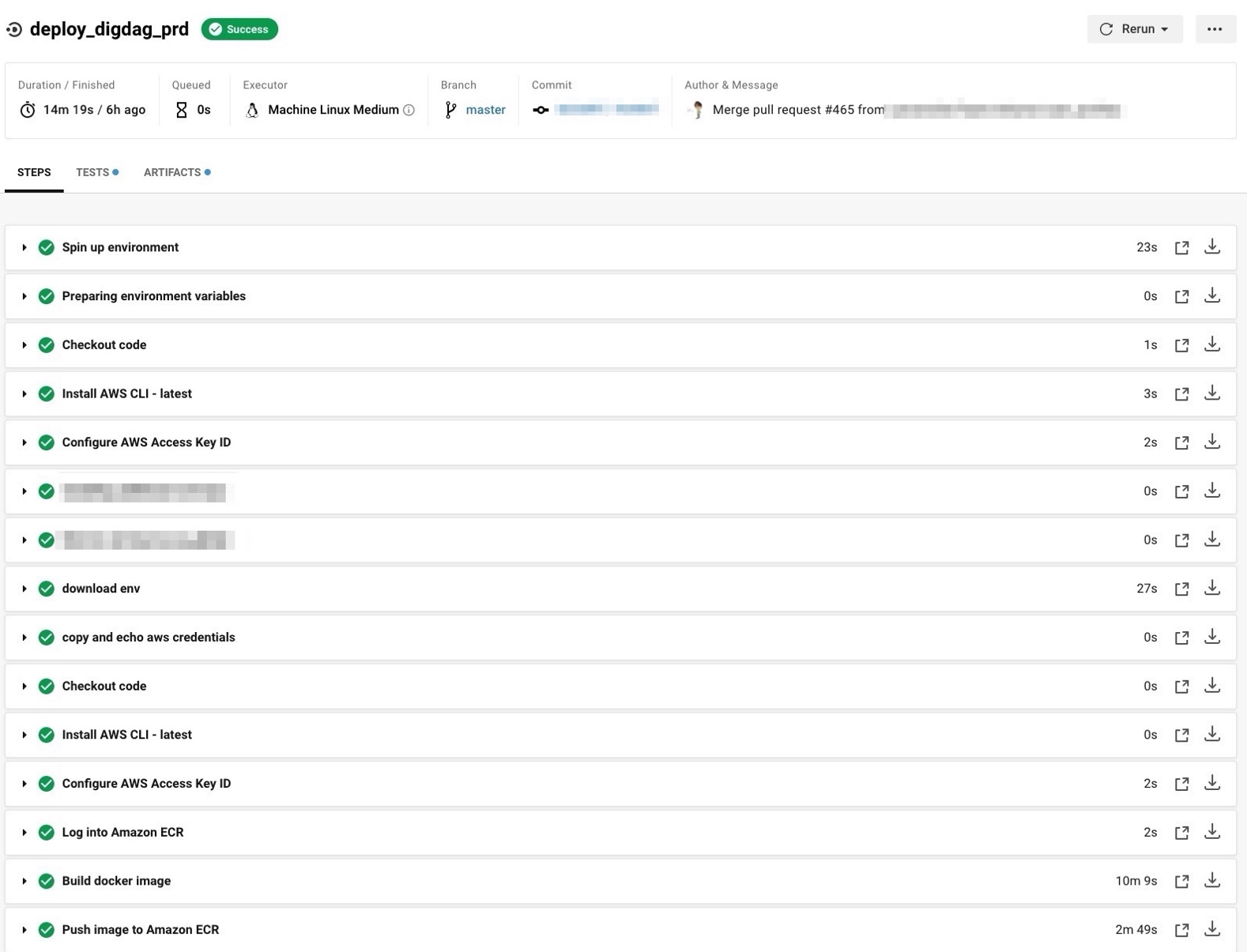
デプロイに時間がかかると、コンテナ化のデメリットが目立ってしまいます。上記にも書きましたが、別のリポジトリで管理しているGoのプログラムがあるため、git cloneしてdep ensureをしている際にデプロイに10分以上かかってしまっているため、リポジトリをまずは一つにまとめてバイナリファイルのみを配布するように改善していこうと思います。
- DigdagコンテナのCPU使用率が高い

コンテナのCPUは2coreでメモリーが2GBなのですが、スケールアップか、Digdagのチューニングをする必要があるかと思いますが、一旦は様子見して改善していきたいと思います。たた、Fargateであるとコンテナがもし落ちてしまっても自動起動されるので運用は非常に楽になります。
- Rubyでデータを一部加工しているプログラムの移行
ユーザー情報テーブルの各カラムなどをSQLで取得して、その日にアクセスしたユーザー一覧を取得しているプログラムがRubyで作られているのですが、これもEmbulkに移行しないとEC2サーバーを削除できないので、頑張ります…!
まとめ
コストはEC2と比べて少し割高になり、構築していて途中EC2でもいいんじゃない?と疑問を持ちましたが、Dockerによる属人化の廃止とバージョンアップのしやすさにより非常にメンテナンスしやすくなったと感じました。
ランサーズではSREチーム大募集しております。少しでも気になった方はDMください!一緒に分析基盤改善していきましょう!