
さあて!!Lancers(ランサーズ) Advent Calendar 2018 がついに始まりました。1日目は @numanomanuさんの「誰も教えてくれない、サービスを終了する技術〜 SPA で作ったサービスを閉じる時にやるべきこと 〜」
SREの@adachin0817 が担当します。
ランサーズでは2018年今年から分析基盤を創り上げていきました。今回は今流行りの分析基盤をどのように運用しているか、どのような技術を使っているのか簡単にご紹介できればと思います。
ランサーズ分析基盤の始まり
もともと@g0dgardenさんが設計を考えて、私が5月にジョインして引き継ぎをしました。
capybara(カピバラ)!!
カピバラといえば草を大量に食べて蓄えている印象からデータ分析に近い存在なので決まったそうです(ロゴとか真面目に作りたい)

SRE本の中にも分析基盤によるログの可視化は該当するので、私にとってはちょうどいいタイミングとチャレンジできるといったところですね!まずはシステム構成図と各チームでの役割について書いていきます。
システム構成図


各チームでの役割

・Redash
これは割愛したいところですが、弊社ではGoogleアカウントでログインでき、DBはRDSで管理しています。従って、間違えてData Sourcesの登録を削除して、クエリを全て消えても元に戻せるようになっています。またRedashは常に最新のバージョンを保つよう運用しています。工夫していることは @waldo0515さんが作成した以下より、Redash自体のモニタリング!時間帯別に実行している時間、重いクエリ、BigQueryのユーザ別コストを可視化しています。

・td-agent/Athena
アプリケーションログはtd-agentでログサーバに集計し、S3に同期しています。また、Athenaへのアクセスログを同期する方法としては以下のように工夫をしています。
- アクセスログをLTSV形式にする⇛アクセスログを解析しやすく, 項目追加など変化に強い形になるため
- S3へ保存するログファイルをtdでJSONにする
- S3バケットのディレクトリ設計。HIVE形式にする⇛全ファイルを探索すると、その分課金されてしまうため必要な分のみ
- パーティションを認識させる
これ実現することで、毎回サーバに入ってawkからの加工などがなくなり、運用コストが下がりました。
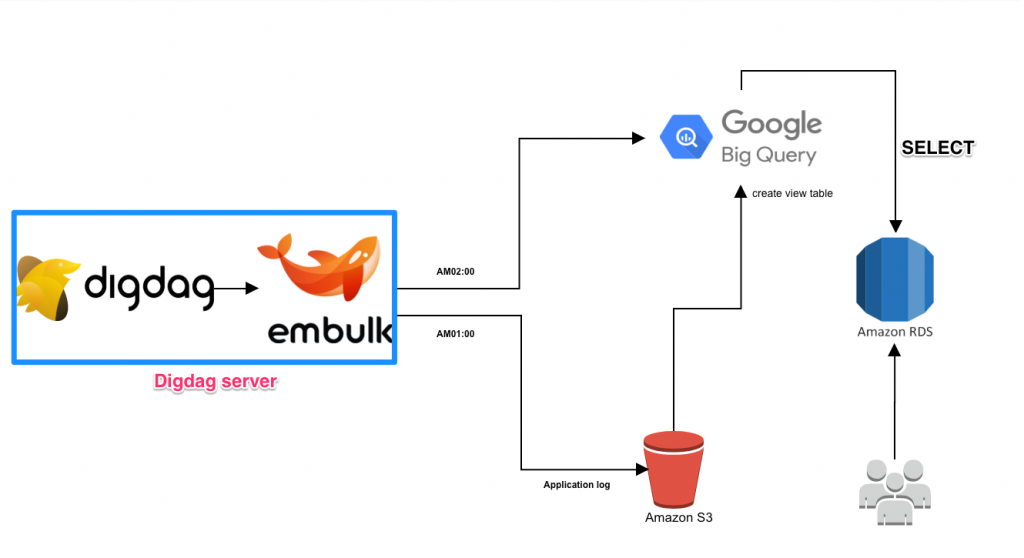
・embulk/Digdag/BigQuery
BigQueryはembulkを使って、S3やRDSのデータを日々Digdag(ワークフローエンジン/ジョブスケジューラ)を使って同期しています。エラー等出たら、slackで通知が来て、以下Digdagコンソールからポチっと押すだけで再同期されるのも手軽です。

BigQueryは仮想テーブルを作成するviewという機能があるので、分析用に加工されたtableでさらに加工することが可能です。また上記にもある各チームでの役割で、アプリ側/Dev開発チームがtdの設定をして、SREチームがDigdagや、embulkの設定をしています。そうすることでスムーズに依頼と作業が進められているのもメリットとSREチーム全員が対応できるよう回しています。またBigQueryはスキャンしたデータ容量によって重量課金する仕組みなので、下手にメンバーがしくじらないよう、アカウント作成時に以下のスライドで共有もしています。RedashではTotal MByte Processed Limitの設定をしているため、クエリのコスト上限もしています。他にも気をつけることがあるので、以下にまとめてみました。
・BigQueryを使用するにあたって注意点
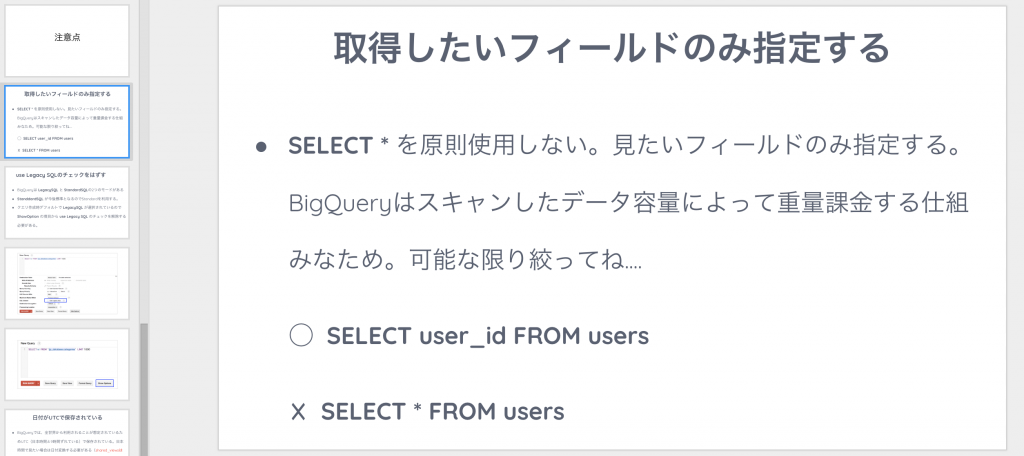
- use Legacy SQLのチェックをはずす(新UIだとデフォルトかも?)
・BigQueryは LegacySQL と StandardSQLの2つのモードがある
・StanddardSQL が今後標準となるのでStandardを利用する
・クエリ作成時デフォルトで LegacySQL が選択されているので ShowOption の項目から use Legacy SQL のチェックを解除する必要がある - 日付がUTCで保存されている
・BigQueryでは、全世界から利用されることが想定されているためUTC(日本時間と9時間ずれている)で保存されている
・下記のようにcastしてJSTに変換しましょう
SELECT cast(FORMAT_TIMESTAMP("%Y-%m-%d %H:%M:%S",p.created,'Asia/Tokyo') as datetime)
- Redashからのスケジューリング
・BigQueryなどをRedashから定期実行する場合は、Queryを投げる度にコストがかかるため、過度な自動更新は辞めましょう
・RDSからBigQueryに同期の際気をつけていること
例えばこのテーブルをBigQueryに投入お願いします!と依頼が来た場合、毎回各テーブルのレコード数を確認しています。
mysql> select count(*) from hogehoge; +-----------+ | count(*)| +-----------+ |1500000| +------------+ 1 row in set (0.00 sec)
上記だと150万レコードをBigQueryに同期する分にはembulkのデータ転送に時間はそこまでかかりません。なので1000万レコード以上の場合は以下のように別テーブルで保存し、差分のみ取るようにして、それ以下は上書き(replace)するようにしています。
・hoge.yml.liquid
in:
type: mysql
{% if env.EMBULK_ENV == 'prod' %}
{% include 'db/prod_DB' %}
{% else %}
{% include 'db/pre_DB' %}
{% endif %}
query: |
SELECT
xxx,xxx,xxx,xxx,xxx,xxx,xxx,xxx,xxx,xxx
FROM
results
WHERE
modified > DATE_SUB(CURDATE(), INTERVAL 1 DAY)
・hoge.dig
_error: sh>: export $(cat config/env | xargs) && /redash/digdag/post_slack.sh "[${session_time}][${session_id}] DigDag Fail xxxxxx" +payments: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/hoge.yml.liquid +transform: bq>: queries/hoge.sql destination_table: hogehoge write_disposition: WRITE_TRUNCATE
続いては分析基盤を応用したランサーズの新機能である「ユーザレポートのアナリティクス」の実装したお話をご紹介します。
ランサーズ/ユーザレポート/アナリティクス

・構成図
・BigQuery/profile_views
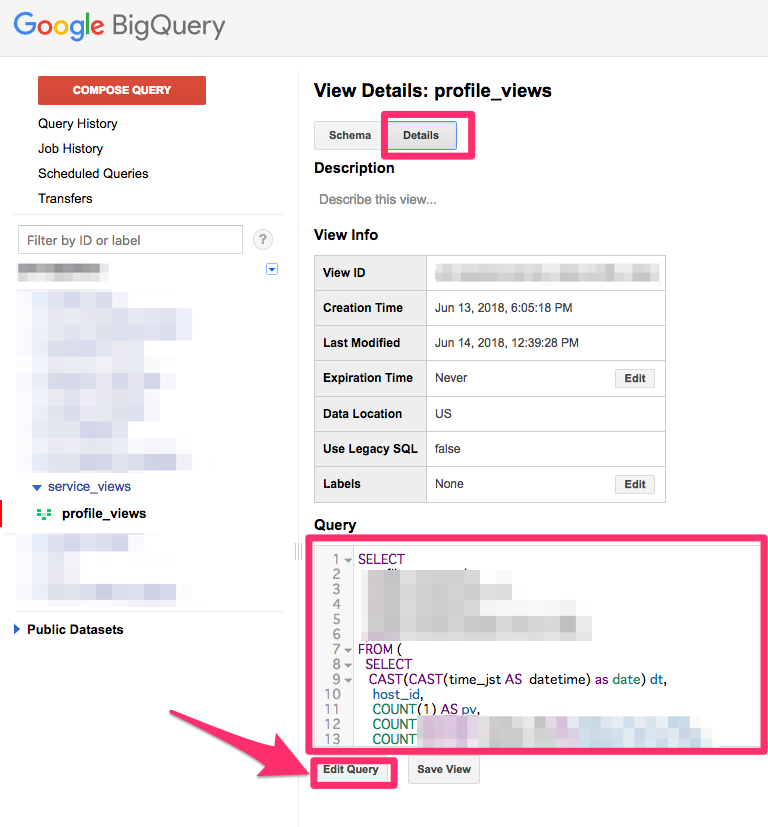
プロフィール数とプロフィールを見たクライアントの可視化はPHPで今年新卒の森泉くん(@IZUMIRU0313)に実装してもらいました。流れは深夜にアプリケーションログをviewに作成し、続いてviewテーブルからRDSへ同期しています。(embulk-input-bigqueryを使用しています)つまり、BigQueryのviewテーブルからRDSへ同期といういつもの逆を実装しています。その方法については私の個人ブログに詳しく書いているのでぜひ参考にしてみてください。
https://blog.adachin.me/archives/8492
まとめ
この分析基盤は他社でも同じよう運用しているとのことで、初め共有されたときは理解するのに時間がかかりました。。。もちろんcapybaraは大事に大事に育てていきます!明日は同じSREチームのyuu26さんです。