ランサーズのデータ分析 – 活用事例 –
ランサーズ社ではデータ分析からレコメンドという形で価値を生み出しています。レコメンドについて簡単に説明した上で、ランサーズ社ではどのようにレコメンドを実装しているかを紹介します。
はじめに
ランサーズにおけるデータ分析の活用事例を紹介したいと思います。
まず、データ分析でできることをまとめました。

データは生の状態では大して価値はありません。データは原油と同じで、精錬され石油となって初めて価値が生まれます。「アマゾノミクス データ・サイエンティストはこう考える」この本の中でデータを精錬することの大切さが説かれています。
また、データ分析に興味がある方はこちらの本を読むことを強くおすすめします。「ビッグデータ分析・活用のためのSQLレシピ」
個人的にはこの本を読んで初めてデータ分析になぜ価値があるのかがはっきりわかりました。
レコメンドについて
レコメンドのパターンは大きく次の3つに分類されます。
- 協調型推薦
このアイテムを買った人はこのアイテムも買っています、というアプローチ - 内容ベース型推薦
アイテムの特徴を利用してアイテムを推薦するアプローチ - 知識ベース型推薦
賃貸物件の検索サイトなどでよく使われる手法で、条件を絞っていき、希望のアイテムを見つけるアプローチ
レコメンドのパターンについてまとめました。

ランサーズ社のレコメンドでは、内容ベース型推薦を使ったアプローチを採用しています。内容ベース型推薦では、アイテムの特徴が類似しているものをレコメンドします。アイテムの特徴として、タイトル・本文・出品情報を利用しています。
レコメンドをより深く知りたい方はこちらをご参照ください。
レコメンドの対象
ランサーズは仕事を発注したい人と仕事を受注したい人を結びつけるプラットフォームです。そのため、発注された「仕事」と「ユーザ」がレコメンドの対象となります。なお、ユーザは受注ユーザと発注ユーザの2パターンに分類できます。
「仕事」と「ユーザ」をレコメンドの対象とするにあたり、それぞれ考慮しなければならない性質がありました。
- 仕事
数週間程度で入れ替わる。
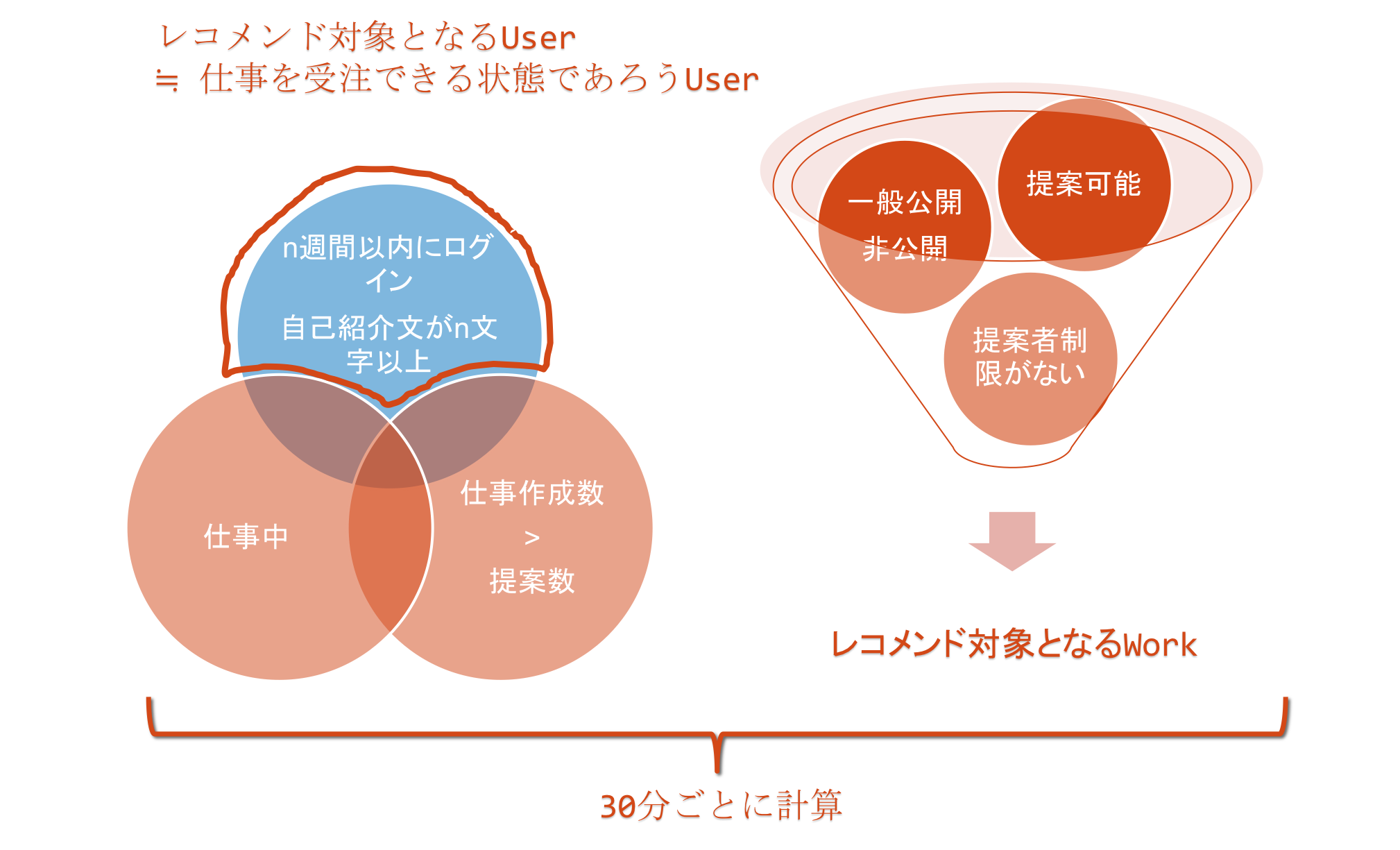
ランサーズの仕事には提案可能状態という有効期限があるので、レコメンドの対象としては提案可能な仕事のみをレコメンドする必要がありました。提案ができない状態の仕事をレコメンドすると、提案ができない仕事はレコメンドしないでほしい旨の問い合わせが少なからずありました。ECサイトで言うと、製造中止になり、購入できない商品をレコメンドするようなものです。 - ユーザ
仕事を受注できる状態のユーザを算出する必要がある。
仕事に対してこの仕事におすすめのユーザは誰か、というレコメンドを行うため、ランサーズに登録しているユーザのうち、仕事を受注できる状態のユーザを算出します。 下図のように差集合を取ることで、仕事を受注できる状態のユーザを算出しました。
レコメンド手法
レコメンドの手法としては上記で言及したように内容ベース型推薦のアプローチを取っています。
- レコメンドの対象となるデータを取得
具体的には主に次の2つをレコメンドの対象としています- 仕事を受注できるであろうユーザ
- 提案可能状態の仕事
- 形態素解析-分かち書き
レコメンドの対象となるデータを全て形態素解析して分かち書きします。- 形態素解析エンジン: mecab-python3
名詞だけ使用しています。 - 辞書: mecab-ipadic-neologd
毎週月曜日と木曜日に辞書データが更新されるので、そのタイミングに合わせてcronで最新データを取得する運用をしています。
- 形態素解析エンジン: mecab-python3
- TF-IDF
レコメンドの対象となるデータ間でのTF-IDF値を求めます。TF-IDFについて詳しく知りたい方はこちらをご参照ください。- scikit-learnというライブラリを使ってTF-IDF値を求めています。
- 算出したTF-IDF値をpickle化し、gzipで圧縮した上で、Redisに保存します。
- レコメンドの事前計算を実行する対象
アクセスのたびにレコメンド計算を実行すると、レスポンスの遅延につながるので、アクセスされる可能性の高いユーザ・仕事に対してのレコメンドを事前に計算します。
以下4パターンを事前に計算します。- ユーザ-ユーザ
ユーザプロフィールページにユーザのレコメンドを出しています。ページのユーザと類似する仕事を受注できるであろうユーザをレコメンドしています。 - ユーザ-仕事
ユーザ(受注)のマイページにそのユーザにおすすめの仕事として、提案可能状態の仕事をレコメンドしています。 - 仕事-ユーザ
ユーザ(発注)のマイページにそのユーザが発注した仕事に対しておすすめのユーザをレコメンドしています。 - 仕事-仕事
仕事ページに類似する仕事としてレコメンドしています。
- ユーザ-ユーザ
- 類似度計算
内容ベース型推薦では、コサイン類似度を用いて類似度を計算します。Redisに保存しておいたTF-IDF値を取り出し、その値を使って類似度を計算する対象のTF-IDF値を求めます。求めたTF-IDF値とRedisに保存しておいたTF-IDF値とのコサイン類似度を求めます。そうすると、類似度を計算する対象のデータとレコメンドの対象となるデータとの類似度が算出されます。算出された類似度の高いデータを抽出すれば、レコメンドすべきデータが求まったということになります。 - レコメンドデータの保存
4で対象としたデータ全てに対して類似度計算を実行し、算出された類似度の高いデータをRedisに保存します。類似度計算は少々コストが高いので、キャッシュしておくことでレスポンスを速めます。
1-6の処理を30分ごとにcronで定期実行しています。事前に類似度を計算しなかったデータに対してアクセスがあった場合は、ステップ5の処理をリアルタイムで実行しています。
さいごに
ランサーズ社はデータ分析・機械学習を用いた施策をこれからさらに拡大します。ランサーズ社でデータ分析・機械学習を使ったシステムを0から作りたい方はご気軽にご連絡ください。また、ランサーズ社の開発体制がどうなっているかなど興味がある方もぜひご連絡ください。
Posted by 高田茂臣(takada.shigeomi@lancers.co.jp)