
はじめに
開発部の吉本です。
一泊二日で、ランサーズ開発合宿を熱海で行いました。
一泊二日で、ランサーズ開発合宿を熱海で行いました。
クローラー開発チームでは、自社の外部サイトや提携サイトの仕事案件をランサーズの仕事検索に表示するという目的で、クローラーを開発して外部サイトとのデータ連携を行いました。
データ連携の全体像
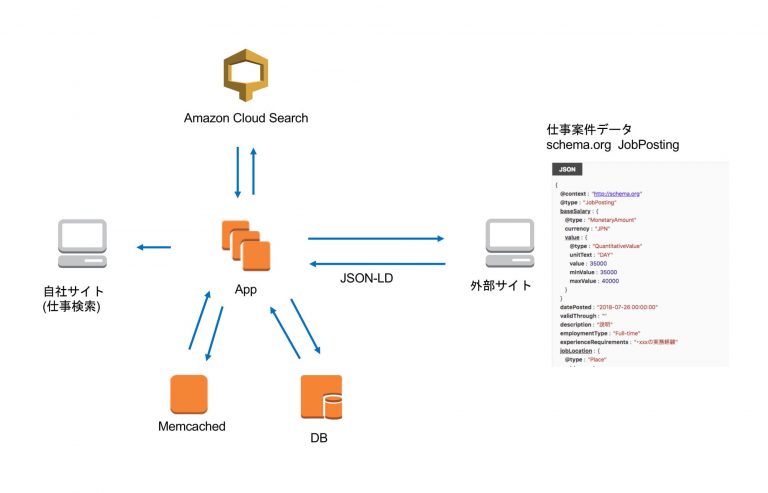
主に以下の2つの処理に分けられます。
- 案件をクロールしてCloudSearchに追加するバッチ処理
- 案件を表示する仕事検索のview側処理
1. バッチ処理
案件をクロールするバッチ処理では以下を行っています。
- 案件をクロールして取得する
- 取得したデータをドキュメントとしてDBに保存
- ドキュメントをCloudSearchに追加する
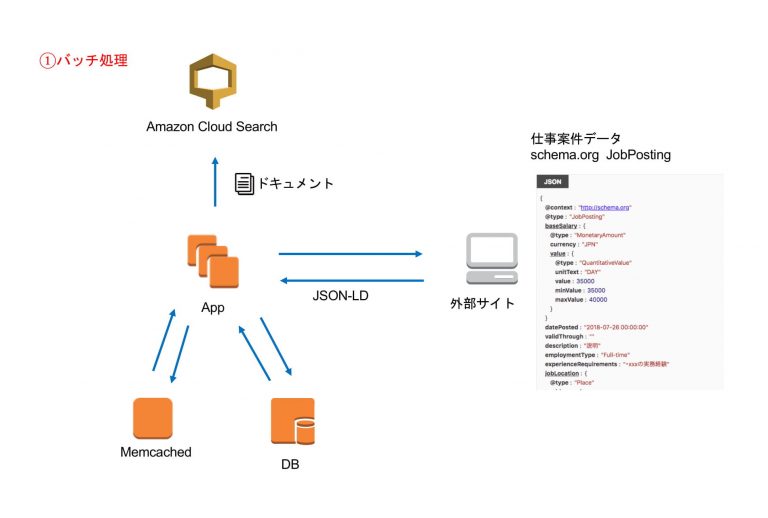
外部サイトの案件をクロール
クローラーで自社の外部サイト、提携サイトの案件の取得を行います。
クロール先では、求人情報の構造化データとして、schema.orgのJobPostingを使用しています。
schema.orgとは、正確な情報を検索エンジンなどのクローラーが認識するための、構造化データのマークアップです。統一した規格でデータを用意することで、複数の外部サイトで同じ形式でデータを取得することができます。
CloudSearchに追加
取得したJSON-LDをCloudSearchのドキュメント形式に変換して追加します。
ドキュメントをDBに保存しておくことで、変更があった時に差分のみ更新できるようにしています。
キャッシュについて
バッチを実行した際に、クロールした案件データを以下でキャッシュして、表示側で読み込む際にはキャッシュを使用しています。
- JSON-LDをキャッシュ (memcached)
2. 仕事検索のview側処理
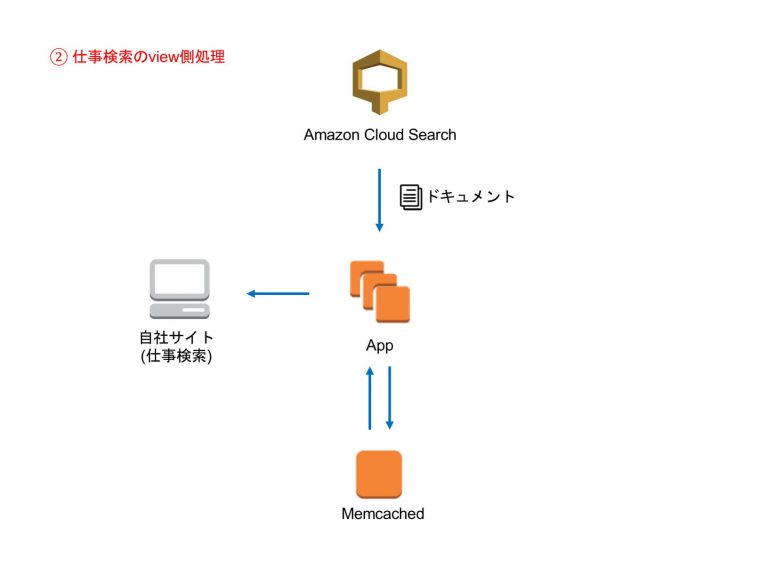
CloudSearchから取得したドキュメントをオブジェクトに変換して、viewに渡すことで、ランサーズ仕事検索に自社の案件と同じ形で表示しています。オブジェクトに変換する際にキャッシュを読み込むことで処理を軽くしています。
クロール先を変更することで、同じ仕組みで複数の外部サイトから案件を取得して表示することができます。今回は、以下のサイトの案件を取得して表示しています。

おわりに
外部サイトの案件を取得するためのクローラーの開発を行いました。
自社の仕事検索において、DBが見れない提携サイトなどを含めたデータ連携を実現しています。
合宿で良かった点としては、以下が挙げられます。
- まとまった時間、いつもと違う環境で短期集中できる
- ペアプロして他の人の開発ノウハウを学べる
- ハマった時にチームですぐに解決できる
合宿の様子
