
ランサーズで機械学習エンジニアをしている高田です。
2018年4月21日(土)にサイバーエージェント主催の30才以下のエンジニアを対象にしたBCU30と呼ばれるカンファレンスで登壇しました。

発表資料です。
300名定員のところに400名以上の応募があり、非常に盛況なカンファレンスでした。
登壇のオファーをしていただいた サイバーエージェント社の飯田 有佳子さんに感謝の言葉を捧げたいと思います。

ランサーズで機械学習エンジニアをしている高田です。
2018年4月21日(土)にサイバーエージェント主催の30才以下のエンジニアを対象にしたBCU30と呼ばれるカンファレンスで登壇しました。
発表資料です。
300名定員のところに400名以上の応募があり、非常に盛況なカンファレンスでした。
登壇のオファーをしていただいた サイバーエージェント社の飯田 有佳子さんに感謝の言葉を捧げたいと思います。
ランサーズ社ではデータ分析からレコメンドという形で価値を生み出しています。レコメンドについて簡単に説明した上で、ランサーズ社ではどのようにレコメンドを実装しているかを紹介します。
ランサーズにおけるデータ分析の活用事例を紹介したいと思います。
まず、データ分析でできることをまとめました。

データは生の状態では大して価値はありません。データは原油と同じで、精錬され石油となって初めて価値が生まれます。「アマゾノミクス データ・サイエンティストはこう考える」この本の中でデータを精錬することの大切さが説かれています。
また、データ分析に興味がある方はこちらの本を読むことを強くおすすめします。「ビッグデータ分析・活用のためのSQLレシピ」
個人的にはこの本を読んで初めてデータ分析になぜ価値があるのかがはっきりわかりました。
レコメンドのパターンは大きく次の3つに分類されます。
レコメンドのパターンについてまとめました。

ランサーズ社のレコメンドでは、内容ベース型推薦を使ったアプローチを採用しています。内容ベース型推薦では、アイテムの特徴が類似しているものをレコメンドします。アイテムの特徴として、タイトル・本文・出品情報を利用しています。
レコメンドをより深く知りたい方はこちらをご参照ください。
ランサーズは仕事を発注したい人と仕事を受注したい人を結びつけるプラットフォームです。そのため、発注された「仕事」と「ユーザ」がレコメンドの対象となります。なお、ユーザは受注ユーザと発注ユーザの2パターンに分類できます。
「仕事」と「ユーザ」をレコメンドの対象とするにあたり、それぞれ考慮しなければならない性質がありました。
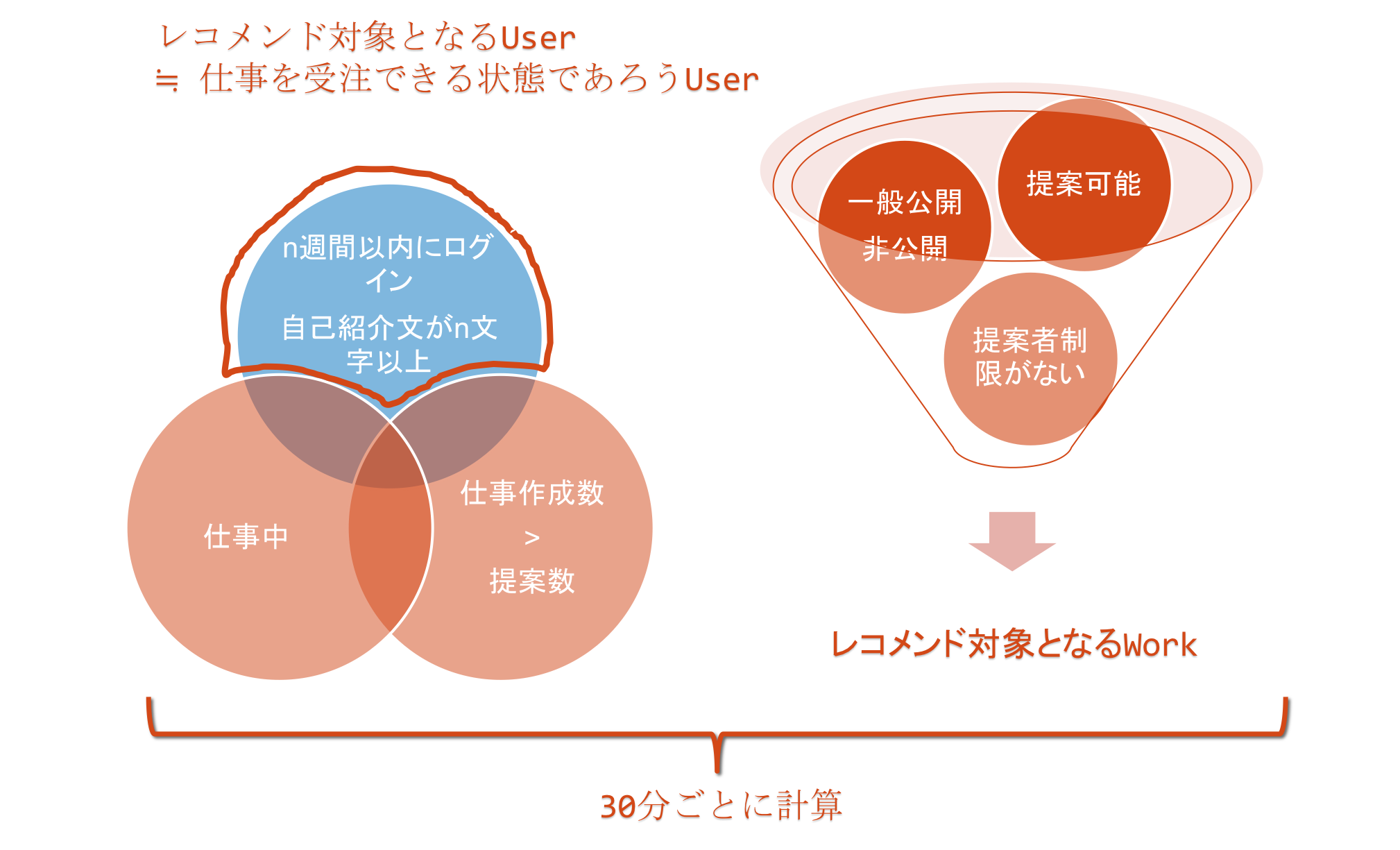
レコメンドの手法としては上記で言及したように内容ベース型推薦のアプローチを取っています。
1-6の処理を30分ごとにcronで定期実行しています。事前に類似度を計算しなかったデータに対してアクセスがあった場合は、ステップ5の処理をリアルタイムで実行しています。
ランサーズ社はデータ分析・機械学習を用いた施策をこれからさらに拡大します。ランサーズ社でデータ分析・機械学習を使ったシステムを0から作りたい方はご気軽にご連絡ください。また、ランサーズ社の開発体制がどうなっているかなど興味がある方もぜひご連絡ください。
Posted by 高田茂臣(takada.shigeomi@lancers.co.jp)
機械学習を使った違反検知の取り組みを日経BP社様に取材していただきました。
ランサーズが「マルチ商法チェッカー」を無償で公開、検知率は99%
マルチ商法チェッカー
https://check.lancers.jp/spam
ランサーズ社では今年の4月頃から毎週金曜日に自分の好きなテーマの開発ができる20%ルールというものを設けました。6月頃から20%ルールの中で機械学習の取り組みが本格化し始め、外部サービスを使って提供していたレコメンドシステムを内製化することを目標として社内から有志が集まりました。毎月利用費を支払っているので、それが0円になれば成果として見えやすいという理由でレコメンドシステムの内製化をテーマとしました。
機械学習の知識が全くない状態からスタートし、徐々に勉強していく中で、レコメンドシステムが形になっていきました。利用していた外部のレコメンドシステムの契約期間が1年の自動更新だったので、更新しないことをその会社に伝えることで退路を断ち、自分たちのモチベーションをより高めました。
特に大きな問題に直面することもなく、8月にレコメンドシステムをリリースしました。
サンプルデータを使ってリアルタイムレコメンデーションを作る
内製化したことで、レコメンドシステムの毎月の維持費を90%削減することができました。その上、仕事への提案率を150%増加させることもできました。
様々な箇所へレコメンドシステムを応用するプロジェクトも計画されており、内製化したことは良いことづくめでした。
レコメンドシステムが上手く稼働したので、機械学習の取り組みは20%ルールの枠を超え、当社のメインプロジェクトへと格上げされました。機械学習を使った次に取り組むべきテーマは何だということになり、今年に入ってから大幅に増加していたスパムメッセージの検知が候補に上がりました。
Lancersプラットフォームでは、ランサーとクライアントがやり取りするためのメッセージ機能を提供しています。このメッセージ機能は誰でも利用できるため、マルチ商法の勧誘に悪用されることが多々あります。
スパムを送信する人は、Sleipnirのような自動化ツールを使って大量のスパムメッセージを定期的に送信するので、正常なやり取りがスパムメッセージの中に埋もれてしまう問題が起こりつつありました。
レコメンドシステムをリリースする中で培った機械学習の知識を使って、スパムメッセージを検知できるようにするプロジェクトが今年の9月から本格的に開始しました。
まずは、スパムメッセージの特徴を掴むところから調査を開始しました。当社にはユーザからの問い合わせ等に対応する専門のチームが存在します。スパムメッセージを見つけ次第、削除するなどの対応を行なっているのもそのチームになるので、そのチームのメンバーに協力を要請し、わからないことは何でも聞ける状況を確保しました。
スパムメッセージを当社のプラットフォーム上で送信することで、スパマーの人たちにとってどういう形でメリットがあるのか、どうやって送信しているのか、どうすれば送信をやめるのか、なぜ送信し続けるのか、などを調査しました。
マルチ商法のような勧誘は、騙されて知らず知らずのうちに加担していた、というケースが大半だろうという先入観があったのですが、調査の中で分かってきたことは、自ら進んで応募しているケースも無きにしも非ず、ということでした。
そのため、ユーザにスパムメッセージを見せないようにするということが、結果として、スパムメッセージを減らすことに繋がるであろう、という仮説を立てました。
次に、スパムメッセージをどうすれば検知できるかということを調査しました。これは機械学習の知識が役に立つ所で、メッセージの本文をTFIDFでベクトル化し、LSAで次元圧縮し、Passive Aggressiveで学習させています。色々試しましたが、速度と精度のバランスがこの組み合わせが最もよかったです。
スパムメッセージ検知システムを作るにあたり、参考になった論文ベスト3です。
1. 不均衡データにおける偽陽性率を考慮したスパム判別器のオンライン学習
2. ビヘイビアベースマルウェア検知におけるオンライン機械学習アルゴリズムの比較評価
3. フィルタ通過スパムメールの特徴と低減法の検討
機械学習を使ったスパムメッセージの検知が上手くいくことがわかったので、次にどのようにランサーズ社のプラットフォームに組み込むかを検討しました。基本的にはマイクロサービスとして検知システムを組み込むということを方針としました。
当社では、ランサーズプラットフォームのフロントエンド、バックエンド、メッセージ機能、インフラの担当者がそれぞれ分かれています。なので、今回のように横断的に機能を拡張するケースでは、プロジェクトリーダー的な役割が必要でした。
今回のケースでは、検知システムを開発する担当者がプロジェクトリーダーとなり、要件定義、仕様定義、検知システムの設計を行いました。
フロントエンド、バックエンド、メッセージ機能、インフラのそれぞれの要件・仕様をGithubのissueに記載することでコミュケーションを行いました。
検知システムの開発と並行してユーザからの問い合わせ等に対応する専門のチームのオペレーションの変更も検討しました。具体的には、検知したスパムメッセージを社内向け管理画面に表示することで非表示等のオペレーションを行えるようにしました。また、そのための人員リソースの調整等も行いました。
以上で検知システムリリースのための準備が整ったため、2017年12月半ばに検知システムをリリースしました。調査開始から約3ヶ月間でのリリースでした。
3ヶ月程度でリリースできたのは、当社が日頃から協力し合う文化を培っていることが大きかったと思います。また、違反検知システムは現場からの発案で、自発的に開始したプロジェクトになります。ランサーズ社は社員にチャレンジすることを推奨しており、チャレンジする人を周りが協力する文化があります。
自発的に物事に取り組みたい人はぜひランサーズ社のエンジニア職に応募してみてください。
https://www.lancers.co.jp/careers/
[2018-02-06 追記]
違反検知システムを「マルチ商法チェッカー」というサービス名で誰でも利用できるように公開しました。
https://check.lancers.jp/spam
Posted by 高田茂臣(takada.shigeomi@lancers.co.jp)
AJAX+ポーリングで実装していたチャットサーバなどを、後付けでwebsocketを使ってリアルタイム通信にしようとすると、図1のような構成になることもあると思います。

まず、端末Aと端末Bがそれぞれsocket.ioライブラリを使ってwebsocketコネクションを確立
1. AJAXでメッセージをPOST
2. メッセージの内容をDBに保存
3. 端末Bに新しいメッセージが作成されたことを伝えるためにsocket.io-php-emitterライブラリを使ってイベントをemit(パブリッシュ)する
4. node.jsが3のイベントをsocket.io-redis
ライブラリを使ってサブスクライブする
5. node.jsは、端末B, C, D…に対して新しいメッセージの内容とともに画面を更新するためのイベントをemitする
図1の構成のシステムがすでにある状態で、websocketで繋がっている端末A, B, C…にPythonでイベントをemitしたい場合の方法を紹介します。基本的には図1のステップ3で行なっていることと同じことをPythonで実行するだけです。構成としては図2のようになります。

PythonにもPHPのようにsocket.io-php-emitterのようなライブラリがあれば、わざわざブログで紹介するほどのことでもないのですが、Pythonにはsocket.io-emitterを実現するライブラリがありません。
socket.io-redisのProtocolについて言及している項目にPython用のsocket.io-redisが紹介されているのですが、名前空間を指定するOfとルーム名を指定するInが機能していないので使えません。
socket.io-redisはRedisのPublishコマンドを発行しているに過ぎないので、自分でpublishコマンドを構築します。
チャネル名はsocket.io-redisによると次の通りに指定します。
特定のnamespace全体にイベントをemitしたい場合のチャネル名は以下の通り
prefix + '#' + namespace + '#'
特定のnamespaceのroomにイベントをemitしたい場合のチャネル名は以下の通り
prefix + '#' + namespace + '#' + room + '#'
socket.ioの場合はprefixのデフォルトはsocket.ioになります。
namespaceを/とし、room名をroom_777とする場合は、例えば以下のようにchannel_nameを準備します。
prefix = 'socket.io'
namespace_name = '/'
room_name = 'room_777'
channel_name = '{0}#{1}#{2}#'.format(prefix, namespace_name, room_name)
socket.ioのemitで送信されるデータはMessagePackと呼ばれる形式でシリアライズされています。
socket.ioで送信する際のデータの形式は以下の通りです。
data = [
'emitter',
{
# socket.ioはv1からバイナリ形式のデータ(画像・動画)も送信できるようになりました。
# 通常のテキストデータの送信と区別するためにtypeキーが用意されています。
# テキストデータの場合は2をセットし、バイナリデータの場合はは5をセットします。
'type': 2,
'data': [
# emitしたいイベント名をセットします
'my_event_name',
# 送信したいデータを辞書形式でセットします
{
'id': 'message_id',
'created_at': '2017-12-19 14:00:00',
'body': 'message_body'
}
],
# namespaceをセットします
'nsp': namespace_name
},
{
# room_nameをセットします
'rooms': [room_name],
'flags': []
}
]
上記データをmsgpackを使ってシリアライズします。
import msgpack data_packed = msgpack.packb(data) print(data_packed) b'\x93\xa7emitter\x83\xa4type\x02\xa4data\x92\xadmy_event_name\x83\xa2id\xaamessage_id\xaacreated_at\xb32017-12-19 14:00:00\xa4body\xacmessage_body\xa3nsp\xa1/\x82\xa5rooms\x91\xa8room_777\xa5flags\x90'
node.js側に事前にセットしておいたイベント名でpublishすればsocket.ioのイベントがemitされます。
pythonにおけるRedisクライアントはこちら
がおすすめです。
import redis r = redis.StrictRedis() r.publish(channel_name, data_packed)
redisで次のようにコマンドが発行されていれば正常に動作しています。
redis-cli monitor | grep PUBLISH 1513649216.0000000 [0 127.0.0.1:50283] "PUBLISH" "socket.io#/#room_777#" "\x93\xa7emitter\x83\xa4type\x02\xa4data\x92\xadmy_event_name\x83\xa2id\xaamessage_id\xaacreated_at\xb32017-12-19 14:00:00\xa4body\xacmessage_body\xa3nsp\xa1/\x82\xa5rooms\x91\xa8room_777\xa5flags\x90"
Posted by 高田茂臣(takada.shigeomi@lancers.co.jp)
Lancers社ではレコメンドシステムをREST APIとして実装しています。Lancers社のメインサービスはPHP×CakePHPで構築されているのですが、scikit-learnを使いたいので、別アプリケーションとして分離する必要があります。分離した以上は何かしらの方法で通信する必要があるので、直感的に理解しやすいRESTを採用しました。RESTはHTTPプロトコルの上で、特定のリソースに対してGET, POST, PUT, DELETEの4パターンで全ての操作を実現しようというものです。
RESTを学ぶには「Web API: The Good Parts」こちらの書籍がわかりやすいです。
RESTでは、操作する対象データをリソースと呼びます。
RESTでは、特定のリソースをURIで表現します。
URIをどのように設計するかがエンドポイント設計です。
Lancers社の仕事に関するレコメンドシステムのエンドポイントは次の通りです(内部ネットワークのみに解放しているエンドポイントです。外からは繋がりません)
/v1/recommend/works/:work_id /バージョン/アプリケーション名/リソース名/リソースID
アプリケーション名をエンドポイントに含めることで、将来的にアプリケーションが増えた際に拡張するのが容易です。例えば、機械学習を用いて特定のworkがスパムかどうかを判定するアプリケーションを作成する場合は、次のようにアプリケーション名を変更するだけでエンドポイント設計が完了します。
/v1/spam/works/:work_id
RESTのエンドポイントを設計するにあたっては、Github REST APIがわかりやすく、参考になります。
Lancers社で運用しているレコメンドサービスにはWebフレームワークとしてflaskを採用しています。pythonのWebフレームワークとしては
djangoも有名ですが、単純なREST APIを構築する程度であればflaskで十分です。アプリケーションサーバにはgunicornを採用し、起動停止管理ためにinitスクリプトを書いています。
initスクリプトのサンプルです。
https://gist.github.com/shigeomi-takada/bf5f8f12cf01cc2e9d1346ab6b5f6474
アプリケーションのディレクトリ構成は下記のようにしています(一部省略)。
mlはmachine learningの略です。
├── README.md ├── app │ ├── __init__.py │ ├── controller.py │ ├── http │ │ ├── recommend.py │ │ └── validation.py │ ├── ml │ │ ├── __init__.py │ │ ├── similarity.py │ │ └── wakati.py │ ├── mysql │ │ ├── __init__.py │ │ ├── connect.py │ │ └── works.py │ └── redis │ ├── __init__.py │ ├── connect.py │ └── works.py ├── batch.py ├── config.py ├── guniconf.py ├── logs │ └── app.log ├── requirements.txt ├── run.py └── tests
エンドポイント設計に従ってルーティングを書きます。
controller.py
@app.route('/v1/recommend/works/<work_id>', methods=['GET'])
def get_wokrs(work_id):
Validation().get_works(work_id)
return Recommend().get(work_id)
2. 類似度計算で計算した類似度をRecommendクラスのgetメソッド内で返すようにすれば、Webアプリケーションとして成立します。
Posted by Shigeomi Takada(takada.shigeomi@lancers.co.jp)
第1章にて、データセットの準備が整ったので、第2章ではレコメンドを実装していきます。
各仕事データ間の類似度を計算するためには、各仕事データを数値化しなければなりません。当連載では、テキストを数値化するためにTF-IDFという手法を用います。
TF-IDFとは、各文書にとって重要な単語は何であるかを算出してくれる便利な計算式です。詳細な仕組みについては以下のサイトがわかりやすいです。
テキストを数値化するためには、TF-IDF以外にも色々と手法があり、単純に単語の出現数だけを考慮するCountVectorizer、1つの単語だけでなく、対象単語の前後の単語も考慮に入れる Word2Vec, Doc2Vecといった手法も存在します。
scikit-learnにはWord2Vec, Doc2Vecは実装されておらず、gensimと呼ばれるライブラリに実装されています。興味がある方はTF-IDFの代わりにWord2Vec, Doc2Vecを使って特徴を数値化してみてください。
Word2Vec
Doc2Vec
それでは、TF-IDFを使ってサンプルデータを数値化していきます。
ダウンロードしたサンプルデータと同じディレクトリにrecommend.pyを作成します。
with ~ as ~というのは、python3から導入された新しい文法で、コンテキストマネージャと呼ばれています。クラスにおけるコンストラクタとデストラクタをセットにしたようなものです。pythonはクラスにおけるデストラクタの挙動が保証されていないので、コンテキストマネージャが重宝します。
下記コードの場合だと、jsonファイルを読み込み、読み込んだオブジェクトを変数 f にバインドし、json.loadに渡しているという処理になります。with文を抜けると自動的にファイルのclose処理が実行されます。
recommend.py
import json
with open('lancers_recommend_datasets.json', 'r') as f:
datasets = json.load(f)
サンプルデータを読み込むことができたので、TF-IDFが計算できるように形を整えます。
items()というのは、組み込み関数で、辞書のキーと値をタプル形式で返してくれる便利な関数です。サンプルデータは {id1: 'body1', id2: 'body2', id3: 'body3',...} このような形式になっているので、items()を使って各idとbodyを取り出して、items変数に格納していきます。
Pythonではidが組み込み関数として用意されているので、idxという変数名にしています。
items = {
'id': [],
'body': []
}
for idx, body in datasets.items():
items['id'].append(idx)
items['body'].append(body)
dictのキーと値を1行で取得する方法。
リストの内包表記というテクニックを使います。
my_dict = {777: 'casino'}
key, val = ([(k, v) for (k, v) in my_dict.items()])[0]
print(key, val)
777 casino
scikit-learnではTF-IDfはTfidfVectorizerという名前で実装されています。
オプションについて
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(
max_df=0.5,
min_df=5,
max_features=1280
# stop_wordsは例えばこのような形で指定します。
stop_words=['あり', 'なし', 'その他'],
analyzer='word',
ngram_range=(1, 1)
)
# tfidf.fit_transform(items['body'])のようにまとめて実行する
# こともできますが、TF-IDFの計算結果を使い回すので、あえて分けて
# 実行しています。
tfidf_fit = tfidf.fit(items['body'])
tfidf_transform = tfidf.transform(items['body'])
print(tfidf_transform.shape)
>>(10000, 1280)
max_featuresでTF値の高い特徴(文字)上位1,280のみをボキャブラリー構築に使用すると指定したので、当然ながら10,000の文書に対してボキャブラリーの数、つまり、特徴量(次元)は1,280となっています。
10,000も文書があるのにたったの1,280単語しか使わないのかと不思議に思われる方もいらっしゃるかもしれませんが、無駄な特徴が多いとむしろ精度が下がります。例えば、max_featuresを設定せずに計算したTF-IDF値を学習データとして用いると、そこそこ精度が落ちます。また、特徴量が多すぎると過学習してしまうので、特徴量はできる限り少ない方が望ましいです。
max_featuresを1,280にしている理由は、別の機会に説明させていただきます。
さらにこの1,280の特徴量を128次元まで圧縮します。
テキストを特徴量に用いると特徴量が増大しがちなので、次元圧縮が重要になります。
KernelPCA, LSA, Random Projectionが次元圧縮の手法として有名どころです。
– KernelPCAはLSAと同じ精度が出るが、処理コストが高すぎる。処理が終了するのに何十分もかかる。
– Random Projectionは速いが、精度がKernelPCA、LSAと比べて10%低かった。
– LSAはKernelPCAとほぼ同じ精度でRandom Projectionより少し遅いくらい。
それぞれ試してみたところ、LSAが速度と精度のバランスが最も良かったです。LSA: Latent Semantic Analysisは、検索の分野でよく使われるので、LSI: Latent Semantic Indexingと呼ばれたりもします。
こちらの論文にRandom ProjectionとLSAについての言及があります。
scikit-learnでは、LSAはTruncatedSVDという名前で実装されています。
当連載で次元数を128としている理由は2つあります。
1. 公式ドキュメントにオススメは100、と書いてある。
For LSA, a value of 100 is recommended.
2. 「情報推薦システム入門 -理論と実践-」 こちらの書籍に、「実験の結果から、次元は128以上にしてもさほど変わらなかった」という記述がある。
実際に、次元を100, 200, 500, 1000で試したところ、大して精度は変わりませんでした。なお、1000次元にすると処理の完了までにだいぶ時間がかかるようになります。
サンプルデータを使って色々試してみてください。
from sklearn.decomposition import TruncatedSVD lsa = TruncatedSVD(n_components=128, random_state=0) # TF-IDFの場合と同じく、lsa.fit(tfidf_transform)のように # まとめて実行することもできますが、計算結果を使い回すので、 # あえて分けて実行しています。 lsa_fit = lsa.fit(tfidf_transform) lsa_transform = lsa.transform(tfidf_transform)
これでデータセットの前処理が完了しました。
本連載では、アイテムの特徴を利用して、類似するアイテムを推薦します。「情報推薦システム入門 -理論と実践-」 こちらの書籍に詳細について記載がありますが、アイテムの特徴を利用した類似度の計算方法はコサイン類似度という計算手法が最も精度が高いです。本連載でもコサイン類似度を使って推薦を実装します。
scikit-learnではコサイン類似度はズバリcosine_similarityという名前で実装されています。
cosine_similarityは、第一引数と第二引数間の類似度を全て計算します。
サンプルデータは10,000件あるので、10,000件それぞれに対して10,000件の類似度を計算します。
from sklearn.metrics.pairwise import cosine_similarity cos_sim = cosine_similarity(lsa_transform, lsa_transform) print(cos_sim.shape) >> (10000, 10000)
cosine_similarityは返り値をnumpyのndarrayという型で返します。
numpy.ndarray方には、argsortというメソッドが用意されています。argsortは、降順に並べ替えた結果の配列のインデックスを返します。
# 1000番目のデータを表示します
print(items['body'][1000])
# 1000番目のデータと類似するデータ上位8件を取得します
sim_items_idx = cos_sim[1000].argsort()[:-9:-1]
# 1番目は自分自身になるので2番目以降を対象とします
for idx in sim_items_idx[1:]:
print('------------------------------------')
# 1000番目のデータと類似するデータの先頭60文字を表示します
print(items['body'][idx][0:60])
$ python recommend.py
急募 モバイルサイト 製作 募集 依頼 目的 概要 当社 フレッツ 大手 固定 通信回線 取り次ぎ 受注 獲得 モバイル リニューアル 運び 現在 運用 サイト 元 モバイルサイト リニューアル 募集 検討 基準 モバイル 市場 参入 成果 モバイル 市場 モバイルサイト 企画 製作 運営 経験 優遇 モバイル 展開 検索連動型広告 展開 希望 デザインソースファイル ファイル 一式 サンプル 製作 実績 モバイルサイト お知らせ 参考 サイト
------------------------------------
急募 モバイルサイト 製作 募集 依頼 目的 概要 当社 フレッツ 大手 固定 通信回線 取り次ぎ 受注 獲得 モバイル
------------------------------------
層 ターゲット カラーコンタクトレンズ モバイルサイト 製作 層 ユーザー ターゲット おしゃれ コンタクトレンズ カラ
------------------------------------
クイズ 作家 募集 依頼 目的 概要 現在 弊社 モバイル 韓国語 学習 コンセプト モバイル クイズ サイト 企画 ク
------------------------------------
モバイル 連動 共同購入 サイト 製作 依頼 目的 概要 参考 有名 共同購入 サイト サイト 構築 検討 基準 お客様
------------------------------------
求人 サイト 企画 作成 モバイル 薬剤師 看護師 求人 サイト リニューアル 依頼 目的 概要 既存 薬剤師 求人 サ
------------------------------------
携帯用 ホームページ 作成 依頼 先日 募集 正直 値段 折り合い イメージ 感じ シンプル 感じ ドメイン 使用 携帯
------------------------------------
モバイル 既存 モバイルサイト お呼び 依頼 目的 概要 既存 モバイルサイト 商品 一覧 商品 詳細 部分 合計 ファ
ランサーズでは同じ内容の仕事データが作られることが少なくないで、全く同じ内容のデータがレコメンドされても気にしないでください。
「モバイルサイトの製作」に類似するデータがレコメンドされました。
コサイン類似度の使い方は以上の通りです。
ここまでで計算したTF-IDF, LSAの計算結果は新規データを受け付けた際に使い回すので保存しておく必要があります。
Pythonには、オブジェクトをバイナリ形式に変換するpickleという非常に便利なモジュールが同梱されているのでこれを使います。バイナリにすることで計算済みのTF-IDF, LSAをデータベースに保存することができます。本連載ではRedisに保存します。
Redisとの通信量を減らすために、pickleで変換したデータをgzipで圧縮した上で、Redisに保存します。
pythonには、gzip, bzip2, xzの3パターンの圧縮方式が同梱されています。gzipを採用した理由はこちらを参考にしてください。
pythonからRedisへの接続はこちらのモジュールを使います。また、Redisとの通信回数を減らすためにパイプラインという機能を使います。パイプラインは、クエリーをまとめてRedisに送る機能です。Webシステムのようなリアルタイム性を追求するシステムを構築する場合は、DBとの接続回数を減らすことは処理速度を速くする上で非常に重要になります。特にRedisは、処理全体の大半が通信時間で占められる傾向があります。Redis自体の処理はほぼ一瞬で終わります。
計算済みTF-IDF, LSAデータは、Redisにstring型で保存します。
import pickle
import gzip
import redis
tfidf_pickle = pickle.dumps(tfidf_fit, pickle.HIGHEST_PROTOCOL)
lsa_pickle = pickle.dumps(lsa_fit, pickle.HIGHEST_PROTOCOL)
tfidf_gzip = gzip.compress(tfidf_pickle, compresslevel=9)
lsa_gzip = gzip.compress(lsa_pickle, compresslevel=9)
r = redis.StrictRedis()
# transactionをTrueにすることでトランザクション処理にすることができます。
# 今回はトランザクション処理にする必要がないので、Falseにします
# withはpython特有の文法であるコンテキストマネージャと呼ばれるものです。
with r.pipeline(transaction=False) as pipe:
pipe.set('tfidf:pickle', tfidf_gzip)
pipe.set('lsa:pickle', lsa_gzip)
# まとめて実行します
pipe.execute()
Redisへの保存が完了したので、あとで使い回すことができるようになりました。
結論: gzip compress_level: 9
Pickleでバイナリ化した1.3MBのデータをgzip, bzip2, xzで圧縮したときの一覧
圧縮率は1-9まで選択することができ、9が最も圧縮率が高いです。圧縮率が高いほど元に戻す時の時間が掛かりそうだと直感的には思うのですが、そんなことはなく、どの圧縮率でも元に戻す時間は同じだったので、圧縮率9を使わない理由はないです。
圧縮後のサイズと元に戻す際の時間を考慮すると、gzip compress_level: 9 が最もバランスがよかったのでgzip compress_level: 9 を採用します。
| Format | Size | Compress Time | Decompress Time |
|---|---|---|---|
| gzip compress_level: 9 | 0.758 MB | 0.47 sec | 0.02 sec |
| gzip compress_level: 8 | 0.761 MB | 0.31 sec | 0.02 sec |
| gzip compress_level: 7 | 0.766 MB | 0.16 sec | 0.02 sec |
| gzip compress_level: 6 | 0.768 MB | 0.13 sec | 0.02 sec |
| gzip compress_level: 5 | 0.776 MB | 0.11 sec | 0.02 sec |
| gzip compress_level: 1 | 0.805 MB | 0.08 sec | 0.02 sec |
| bzip2 compress_level: 9 | 0.759 MB | 0.45 sec | 0.13 sec |
| bzip2 compress_level: 8 | 0.762 MB | 0.45 sec | 0.13 sec |
| bzip2 compress_level: 7 | 0.748 MB | 0.45 sec | 0.13 sec |
| bzip2 compress_level: 6 | 0.748 MB | 0.46 sec | 0.13 sec |
| bzip2 compress_level: 5 | 0.753 MB | 0.47 sec | 0.13 sec |
| bzip2 compress_level: 1 | 0.796 MB | 0.45 sec | 0.13 sec |
| lzma format=FORMAT_XZ | 0.633 MB | 0.73 sec | 0.09 sec |
1.はじめにへ戻る
3.Webアプリケーションとしての実装へ続く
Posted by Shigeomi Takada(takada.shigeomi@lancers.co.jp)
当連載ではPython3とscikit-learnを使って実装を進めます。Python3のインストール方法についてはこちらを参考にしてください。
scikit-learnのインストール方法については公式サイトをご参照ください。
Lancers社では仕事詳細ページ下部にそのページの仕事と類似する仕事をレコメンドとして表示しています。
このレコメンドシステムを開発するにあたって得たノウハウを当連載にて共有します。

これらの参考資料を読みこなせば、機械学習を使ったリアルタイムレコメンデーションを作ることができるようになります。
レコメンドのパターンは「情報推薦システム入門 -理論と実践-」によると、大きく次の3つに分類されます。
– 協調型推薦
このアイテムを買った人はこのアイテムも買っています、というアプローチ
– 内容ベース型推薦
アイテムの特徴を利用してアイテムを推薦するアプローチ
– 知識ベース型推薦
賃貸物件の検索サイトなどでよく使われる手法で、条件を絞っていき、希望のアイテムを見つけるアプローチ
当連載では、内容ベース型推薦を使ったレコメンドを実装していきます。内容ベース型推薦では、アイテムの特徴が類似しているものをレコメンドします。アイテムの特徴として、タイトルと本文を利用します。
機械学習において、学習に使うデータをデータセットと呼びます。当連載ではデータセットとして下記サンプルデータを使って実装を進めていきます。
こちらのサンプルデータは、ランサーズ社で一般公開されている仕事データの一部を分かち書きにして、名詞だけを抽出したものです。仕事データのタイトルと本文を連結した上で分かち書きしています。
本文よりもタイトルに出てくる単語を重要視するといったことも考えられますが、誰もがタイトルを上手く付けられるとは限らないので、タイトルと本文に出て来る単語は平等に扱います。
分かち書きの手法についてはこちらを参考にしてください。
サンプルデータは以下のようなJSON形式でデータを保持しています。idは0からの連番を割り当てています。bodyはタイトルと本文を連結して分かち書きにしたものです。
{id1: 'body1', id2: 'body2', id3: 'body3',...}
json形式のファイルをzipで圧縮しています。
サンプルデータ
機会学習させるためのデータに何を選ぶか、選んだデータをどのように加工するかなどを考えることを特徴エンジニアリングと呼びます。機械学習で高い精度の結果を得るためには、特徴エンジニアリングが何よりも重要になります。
学習モデルを作るにあたり、何がそのアイテムを特徴付けているかを人間が考える必要があります。
当連載では各仕事データのタイトルと本文の単語を特徴として使用するので、アイテムを特徴付けるわけではない、不要な単語(特徴)をできる限り取り除く必要があります。
例えば、以下のような文言はランサーズ社の仕事データ内によく出現するにも関わらず、その仕事データを特徴付ける訳ではないので、取り除く必要があります。
宜しく よろしく お願いいたします お願い致します お願いします お願いします ご迷惑をおかけしますが この度はご協力頂き ありがとうございます ありがとうございました 有難うございます 有難うございました いつもお世話になっております
また、下図仕事データの青枠で囲んだ部分のような定型文もランサーズ社の仕事データ内に機械的に出現するだけで、その仕事データを特徴付ける単語ではないので、取り除く必要があります。
文章を特徴付ける単語は、ロゴ, 制作, サイトといったものになります。

サンプルデータは、主な不要単語を取り除いた上で分かち書きしています。
Posted by Shigeomi Takada(takada.shigeomi@lancers.co.jp)
分かち書きとは、テキストを空白区切りにしたものです。
テキストを機械学習させるには前段階としてテキストを分かち書き状態にする必要があります。
なんで休みなく働いている人が偉いの?
このテキストの分かち書き状態は下記の通りです。単語の意味ごとに空白で区切られます。
なんで 休み なく 働い て いる 人 が 偉 いの ?
分かち書き状態にするには、どれが日本語として意味をなしている単語なのかを見分ける必要があります。例えば、な んで 休 みな く働い てい る人が 偉い の? この状態だと分かち書きにはなっていますが、分割されている1つ1つの単語が日本語としては意味をなしていないので、情報としては無益です。なんでという単語が日本語として意味をなしているかどうかを判別するためには形態素解析エンジンを使います。形態素とは、言葉が意味をなす最小単位のことです。
英語は標準で分かち書きスタイルの言語なので、日本語のように手間をかけて分かち書きにする必要がありません。
日本語を分かち書きするには、MeCabという形態素解析エンジンを使います。MeCabよりも高機能を謳っているJUMAN++という形態素解析エンジンもありますが、辞書を使えばそればそれほど大きな差はないように感じるので、本ブログではMeCabを使います。
brew install mecab brew install mecab-ipadic
apt-get update && apt-get upgrade -y apt-get install -y gcc g++ libmecab-dev mecab mecab-ipadic-utf8
MeCab本体には固有名詞が多くは入っていないので辞書をダウンロードします。
mecab-ipadic-NEologdというMeCab推薦の辞書があるのでこれを使います。
-n: 最新版をダウンロード
-a: 全部入り状態でダウンロード
-p: ダウンロードするパスを指定
任意の場所にダウンロードすればよいですが、例えば、~/mecab-ipadic-neologd/mecab-ipadic-neologdにダウンロードするよう指定します。
2GB以上の容量があるので、ネットワーク環境によっては少々時間がかかることもあります。
ダウンロードの途中でyesの入力が求められるので、yesと入力してください。
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git cd mecab-ipadic-neologd ./bin/install-mecab-ipadic-neologd -n -a -p ~/mecab-ipadic-neologd/mecab-ipadic-neologd
ダウンロードが完了したら、動くか試してみます。
mac:~ lancers$ mecab 業務委託C言語 業務 名詞,一般,*,*,*,*,業務,ギョウム,ギョーム 委託 名詞,サ変接続,*,*,*,*,委託,イタク,イタク C 名詞,一般,*,*,*,*,* 言語 名詞,一般,*,*,*,*,言語,ゲンゴ,ゲンゴ EOS
mac:~ lancers$ mecab -d ~/mecab-ipadic-neologd/mecab-ipadic-neologd 業務委託C言語 業務委託 名詞,固有名詞,一般,*,*,*,業務委託,ギョウムイタク,ギョームイタク C言語 名詞,固有名詞,一般,*,*,*,C言語,シーゲンゴ,シーゲンゴ EOS
MeCabが使えるようになったので、次にPythonから使えるようにします。
pip install mecab-python3
MeCabをインポートして何もエラーが発生しなければインストール完了です。
mac:~ lancers$ python Python 3.6.0 |Anaconda 4.3.1 (x86_64)| (default, Dec 23 2016, 13:19:00) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin Type 'help', 'copyright', 'credits' or 'license' for more information. >>> import MeCab
テキストを機械学習させるための前段階としての分かち書き処理は次のステップを経ます。
Taggerクラスをインスタンス化する際には次の2つのパラメータを渡します。
-Ochasen: -Ochasenを指定することでtab区切りになり、返り値が扱いやすくなります。-Ochasenを指定すると次のようになります。
[‘C言語\tシーゲンゴ\tC言語\t名詞-固有名詞-一般\t’]
-d: 使用する辞書を指定します。mecab-ipadic-neologdをダウンロードしたパスを指定してください。
それでは、Pythonで形態素解析します。
# -*- coding: utf-8 -*-
import os, MeCab
document = 'なんで休みなく働いている人が偉いの?'
neologd_path = os.path.expanduser('~') + '/mecab-ipadic-neologd/mecab-ipadic-neologd'
tagger = MeCab.Tagger('-Ochasen -d %s' % neologd_path)
docs = tagger.parse(document)
print(docs)
なんで ナンデ なんで 副詞-一般
休み ヤスミ 休み 名詞-一般
なく ナク ない 形容詞-自立 形容詞・アウオ段 連用テ接続
働い ハタライ 働く 動詞-自立 五段・カ行イ音便 連用タ接続
て テ て 助詞-接続助詞
いる イル いる 動詞-非自立 一段 基本形
人 ヒト 人 名詞-一般
が ガ が 助詞-格助詞-一般
偉い エライ 偉い 形容詞-自立 形容詞・アウオ段 基本形
の ノ の 助詞-終助詞
? ? ? 記号-一般
EOS
tagger.parseの返り値は以下の特徴を持ちます。この4点を踏まえて機械学習に使いたい単語を抜き出します。
形態素解析を実行するメソッドにはtagger.parseToNodeというものもありますが、返り値の扱いがややこしいのでtagger.parseを使います。どちらを使っても結果は同じです。
まず、全体を1行ごとに区切り、リストにします。
str.split(sep): strをsepで区切り、リストで返します。
words = docs.split('\n')
print(words)
['なんで\tナンデ\tなんで\t副詞-一般\t\t', '休み\tヤスミ\t休み\t名詞-一般\t\t', 'なく\tナク\tない\t形容詞-自立\t形容詞・アウオ段\t連用テ接続', '働い\tハタライ\t働く\t動詞-自立\t五段・カ行イ音便\t連用タ接続', 'て\tテ\tて\t助詞-接続助詞\t\t', 'いる\tイル\tいる\t動詞-非自立\t一段\t基本形', '人\tヒト\t人\t名詞-一般\t\t', 'が\tガ\tが\t助詞-格助詞-一般\t\t', '偉い\tエライ\t偉い\t形容詞-自立\t形容詞・アウオ段\t基本形', 'の\tノ\tの\t助詞-終助詞\t\t', '?\t?\t?\t記号-一般\t\t', 'EOS', '']
必要な単語を抜き出して、1つの文字列として分かち書き状態にします。
str.join(iterable): iterable内の文字列をstrで結合して、文字列として返します。
res = []
for word in words:
# EOS, ''の場合は無視
if word == 'EOS' or word == '':
continue
# タブで区切り、リストにします
word_info = word.split('\t')
# 4番目に何詞かが格納されています。動詞と名詞だけを対象にします。
if word_info[3][0:2] in ['動詞', '名詞']:
# 3番目に基本形が格納されています
res.append(word_info[2])
wakati = ' '.join(res)
# 1つの文に対して名詞と動詞の基本形だけが分かち書きされた状態になりました。
print(wakati)
休み 働く いる 人
分かち書きの実装は以上で完了です。これに正規化の処理を加えて、クラス化します。
コードはこちらにまとめました。
正規化に関してはこちらのページを参照してください。形態素解析の精度を落とさないようにするために全角・半角、記号等の扱いを適切にするのが正規化の目的です。
本章で実装した分かち書き処理を使って次章以降を進めます。
3. 特徴化へ続く(Coming soon)
Posted by Shigeomi Takada
ランサーズは、企業などが仕事を依頼し、フリーランサーが自分に合った仕事を選ぶのを手助けするプラットフォームです。
ランサーズでは、依頼された仕事を8つのカテゴリのいづれかに属するように分類しています。依頼された仕事のタイトルからどのカテゴリに属するかを機械学習を使って予測します。つまり、機械学習における分類問題を解きます。
全5回に分けて仕事の分類を実装します。使用言語はPythonです。
MacやUbuntuはpython2系が標準で使用される状態になっているので、最新の3系を使えるようにします。
Anacondaという名前のPython本体と機械学習関連のパッケージを管理するためのツールを使用します。ニシキヘビ(Python)よりも強者であるアナコンダ(Anaconda)という位置付けが名前の由来。
ホームディレクトリにAnacondaをインストールし、ターミナルでpythonと打つと、AnacondaのPython3が使用されるようにします。
brew install wget
wget https://repo.continuum.io/archive/Anaconda3-4.4.0-Linux-x86_64.sh bash ~/Anaconda3-4.4.0-Linux-x86_64.sh -b -p ~/anaconda export PATH=~/anaconda/bin:$PATH echo export PATH="~/anaconda/bin:$PATH" >> ~/.bash_profile
wget https://repo.continuum.io/archive/Anaconda3-4.4.0-Linux-x86_64.sh bash ~/Anaconda3-4.4.0-Linux-x86_64.sh -b -p ~/anaconda export PATH=~/anaconda/bin:$PATH echo export PATH="~/anaconda/bin:$PATH" >> ~/.profile
ターミナルでpythonと入力して下記のように表示されれば正常にインストールできています。python2系が表示される場合は、一度ターミナルを閉じて、再度 python を実行してみてください。
mac:~ lancers$ python Python 3.6.0 |Anaconda 4.3.1 (x86_64)| (default, Dec 23 2016, 13:19:00) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>
以上でPython3の準備が整いました。
Posted by Shigeomi Takada